
Web Scraping with Scrapy and Python - Guide with Real world Example


6 min read
What is Scrapy and what are it's features
Scrapy is a super powerful Open Source Web Scraping tool that can help you extract data with ease.
It works with Python.
I, a data Extraction Expert, have been using Scrapy for years and it's been my go-to when Scraping data from any website.
I combine it with other Technologies like Selenium, Splash, and more to extract large amount of data with ease.
So the main features that make Scrapy a super Powerful open-source tool are:
Allows you to send concurrent requests to a website and extract data asynchronously (sending multiple requests in parallel)
Connects seamlessly with other Technologies like Selenium, Beautiful Soup, Splash, and more. It's the power of Python. Simply import the libraries and start using them
Export the Output easily to CSV, Excel, JSON or database like MongoDB, MYSQL or others.
The features are endless, so now let's get started with using this Powerful Open Source Tool with Python.
Installation
Before we install Scrapy, make sure you have Python downloaded and Installed on your PC. You can download it from here: python.org
Now, to install the Scrapy library and other essential libraries that make it easy to identify any errors if they come, run the below command in cmd:
pip install scrapy pylint autopep8
pylint analyzes your code without running it
autopep8 formats python code
Creating a Scraper folder with Scrapy
Now Lets get the interesting Part: Creating the Spider folder with Scrapy.
In this Article, we will scrape https://books.toscrape.com/ website and get the names of all the books, their prices and their links.
We will also navigate through multiple pages.
To Create a project in Scrapy, run the following command in CMD or Terminal:
scrapy startproject Book_scraping
This will create a folder named Book_Scraping.
Now to go inside the folder, run the command:
cd Book_scraping
Now, before we understand the folder strucuture, let's create a scrapy spider as well which is where we will code our Program that scrapes the data from the website.
The code for creating the spider is :
scrapy genspider spider_name website_domain
To create the Scrapy spider for the Books website, run the following command:
scrapy genspider books_scraper books.toscrape.com
This will create a spider named books_scraper in the Book_scraping/spiders folder for the domain books.toscrape.com
Now, here is the complete structure of our Web scraping project:
.
├── Book_scraping
│ ├── spiders
│ │ ├── __init__.py
│ │ └── books_scraper.py
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ └── settings.py
└── scrapy.cfg
The Main files you will interact the most here are:
books_scraper.py : Coding our main Scraper program here
settings.py : Handling the settings like Speed or our bot, Making our bot undetectable and extra configurations.
Here's a short info about the others as well:
scrapy.cfg: Contains settings such as project name, spider details and other configurations related to deployment.
__init__.py: indicates that spiders directory should be treated as a Python package
items.py: Can be used to collect the scraped data and manage it.
middlewares.py: Allows you to process request before and after they reach the spider.
pipelines.py: extra operations to be performed on the scraped data such as validation, cleaning & storage.
Now enough of the theory, let's get our hand dirty!
Main Scraper Program
Open the main Bot folder in any of your favorite Code Editor. In this demo, we will use Visual Studio code.
And open the file Books_scraping/spiders/books_scraper.py in the editor.
This is how the file should like:
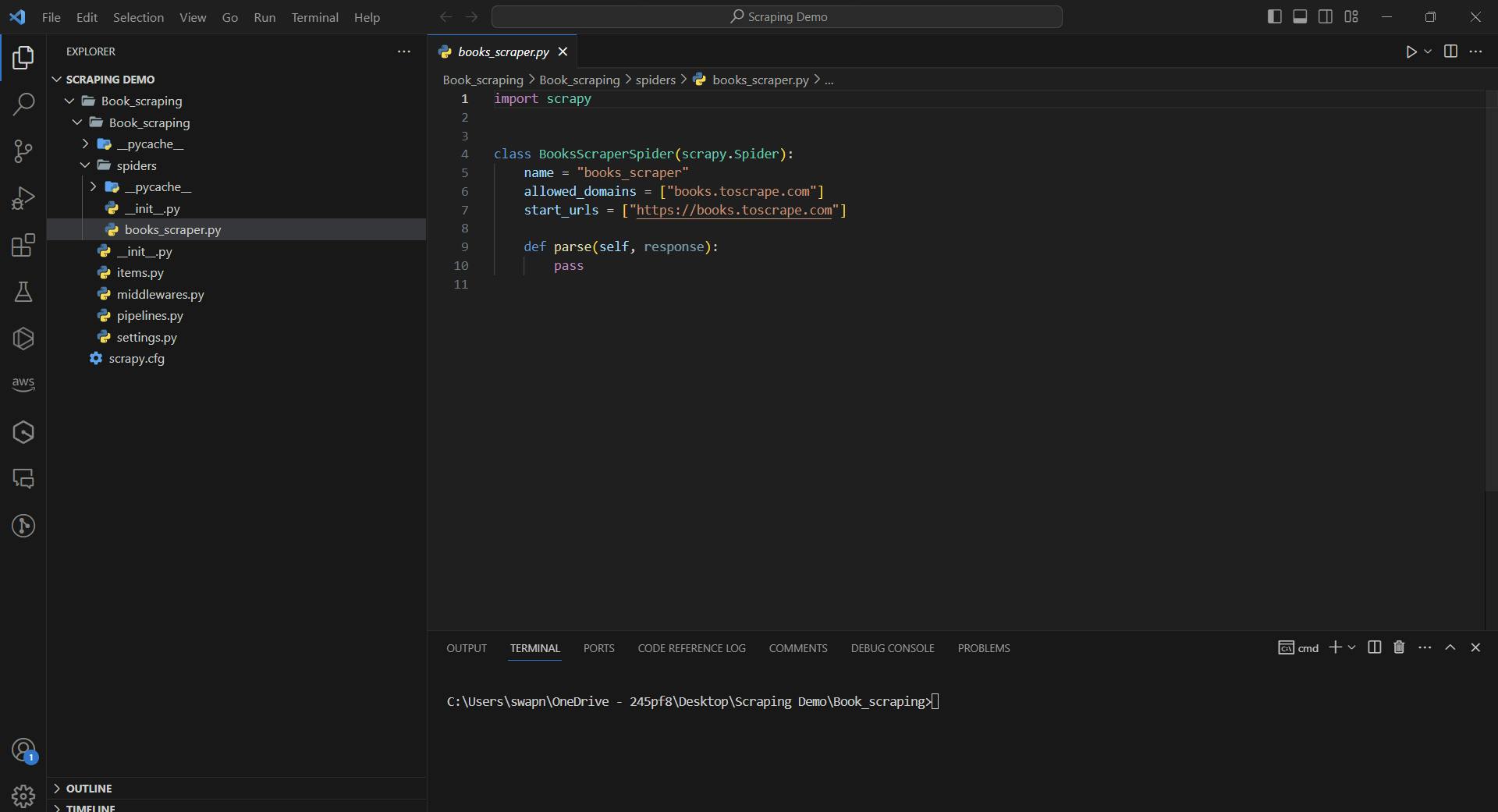
Now it already has some initial code which we can tweak according to us.
start_urls is the starting page you want to scrape data from. We can replace it with another function named start_requests to make it easy for us to pass multiple urls to scrape data.
allowed_domains includes the list of domains that you want to scrape. You can even remove this line to scrape data from multiple websites.
So you can change the code to below:
import scrapy
class BooksScraperSpider(scrapy.Spider):
name = "books_scraper"
allowed_domains = ["books.toscrape.com"]
# Function to send initial Request
def start_requests(self):
# Way to send Request to the first page of the website and call parse function after receiving response
yield scrapy.Request(url='https://books.toscrape.com/', callback=self.parse)
def parse(self, response):
# Printing the body of the page
print(response.body)
So in the above program, we send the request to the first page of the website and then the response is received in the parse function.
Now to run the above program, run the following command in the terminal:
scrapy crawl books_scraper
If everything went correctly, you should get the HTML content of the page in the terminal like below:
Amazing!
Now let's parse the HTML content to just get the names of the book, their prices and their links.
To do this, we need to locate each of the data on the pages.
We can do that with Xpath or CSS Selector. Let's do it with Xpath:
Scraping Data with Xpath
To locate xpath, you can simply create the Xpath by opening inspect element on the page you want to scrape, locate the element and then create the xpath for it.
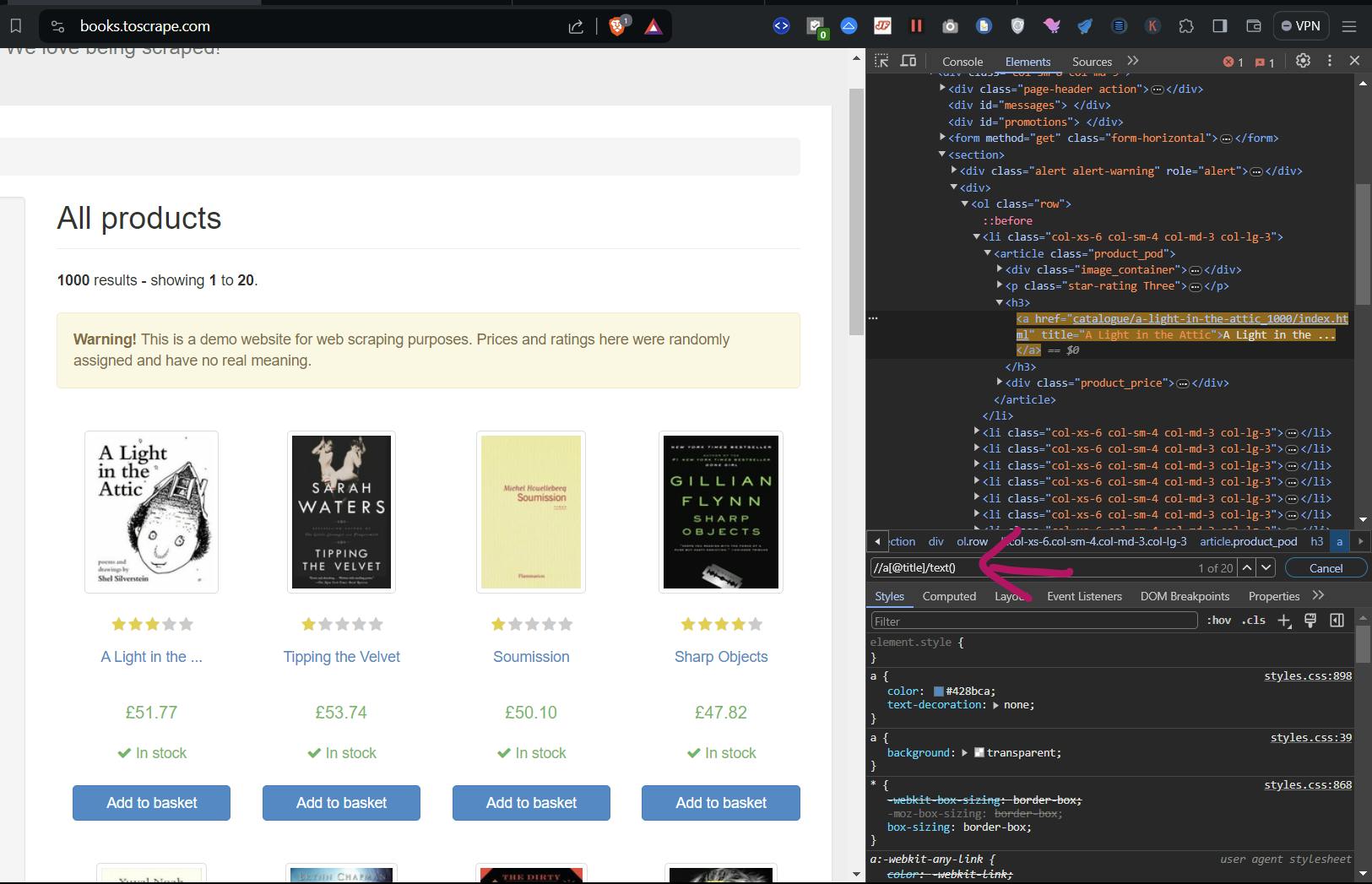
So after finding xpath for each of the data point you want to extract, here is how the code should look like:
import scrapy
class BooksScraperSpider(scrapy.Spider):
name = "books_scraper"
allowed_domains = ["books.toscrape.com"]
# Function to send initial Request
def start_requests(self):
# Way to send Request to the first page of the website and call parse function after receiving response
yield scrapy.Request(url='https://books.toscrape.com/', callback=self.parse)
def parse(self, response):
book_name = response.xpath("//a[@title]/text()").getall()
book_price = response.xpath("//div[@class='product_price']/p[1]/text()").getall()
book_link = response.xpath("//a[@title][@href]/@href").getall()
print(book_name, book_price, book_link)
Now run the program again by running:
scrapy crawl books_scraper
and you will get the name of each of the book, it's price and it's book link. It will be in the list format.
Now to output the request, we can use the yield feature of the scrapy function:
def parse(self, response):
book_name = response.xpath("//a[@title]/text()").getall()
book_price = response.xpath("//div[@class='product_price']/p[1]/text()").getall()
book_link = response.xpath("//a[@title][@href]/@href").getall()
for book_name, book_price, book_link in zip(book_name, book_price, book_link):
yield{
'Book Name':book_name,
'Book Price':book_price,
'Book Link':book_link
}
If you run the Scraper again now, you will get the data for each of the book properly defined as follows:
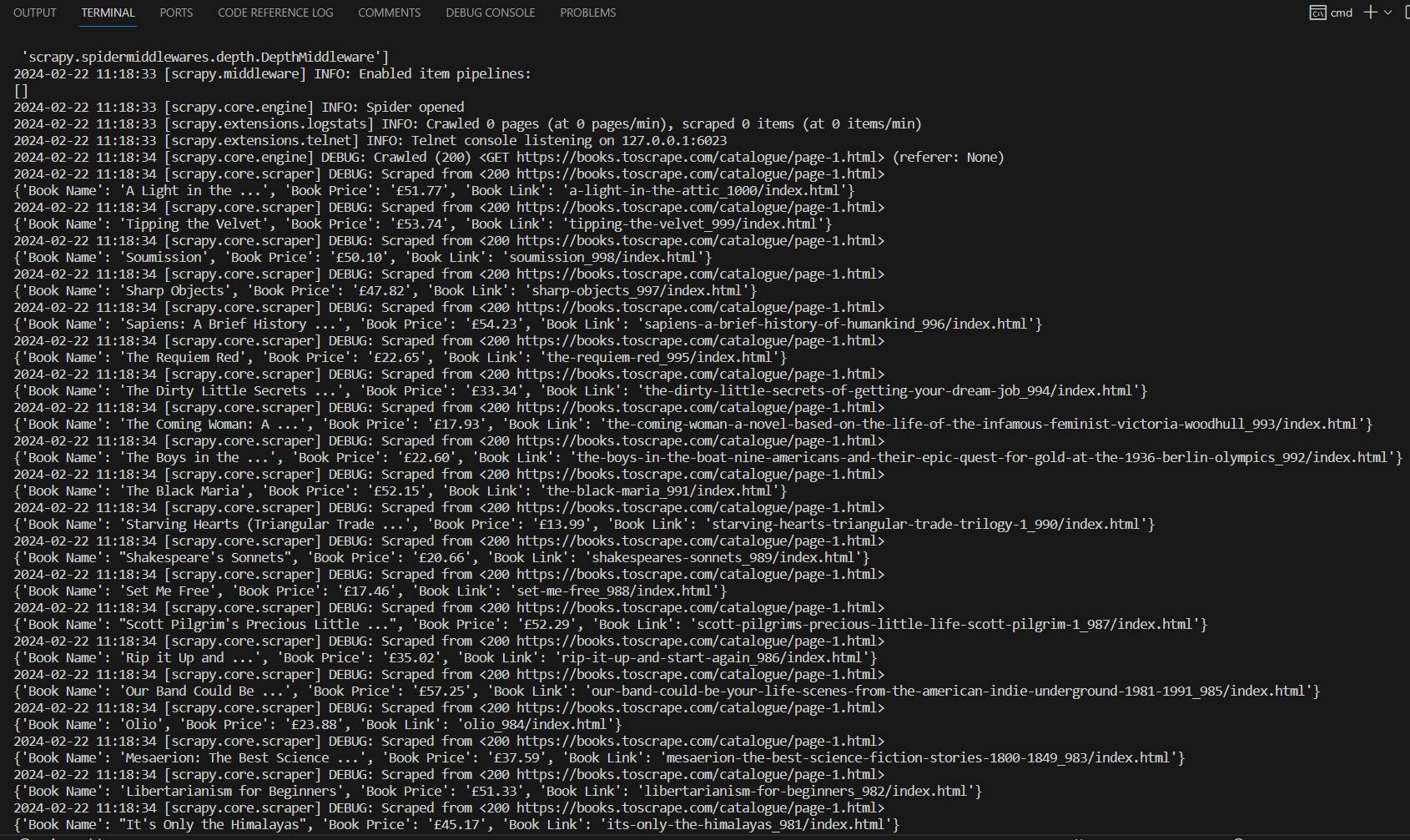
Now, you can even output this data easily to a CSV file with inbuilt scrapy command.
Just add -o Output_file_name.csv to the current command:
scrapy crawl books_scraper -o Output_Sample.csv
This will create a Output sample file in the folder which contains the needed data.
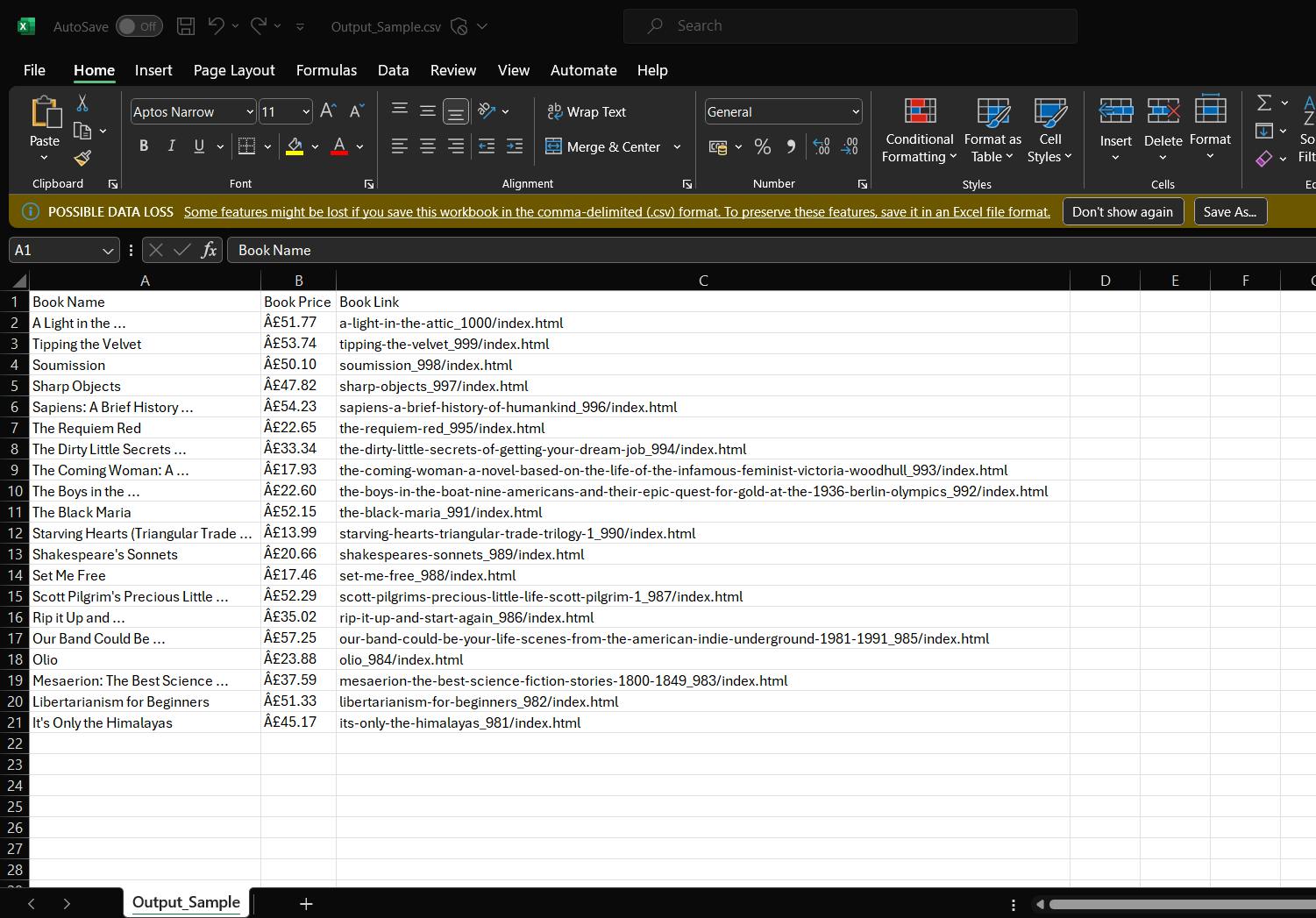
Amazing, isn't it?
Navigating through Multiple Pages
Now to navigate through multiple pages all at once, we can either:
identify the xpath for the next page and iterate through each of the url to get the needed data
Get the URL which contains the page number and Increment the page number of each URL and get the data from each of them
Here's how the second way would work like:
import scrapy
class BooksScraperSpider(scrapy.Spider):
name = "books_scraper"
allowed_domains = ["books.toscrape.com"]
# Function to send initial Request
def start_requests(self):
for page_num in range(1, 10):
page_url = f"https://books.toscrape.com/catalogue/page-{page_num}.html"
# Iterate through each page number
yield scrapy.Request(url=page_url, callback=self.parse)
def parse(self, response):
book_name = response.xpath("//a[@title]/text()").getall()
book_price = response.xpath("//div[@class='product_price']/p[1]/text()").getall()
book_link = response.xpath("//a[@title][@href]/@href").getall()
for book_name, book_price, book_link in zip(book_name, book_price, book_link):
yield{
'Book Name':book_name,
'Book Price':book_price,
'Book Link':book_link,
}
Next Steps
Now that you have learned how Scrapy works, you can try scraping more websites with the help of scrapy.
And if you get blocked when scraping data, you can create an Antibot bypass mechanism mentioned here:
https://www.getodata.com/blog/7-steps-to-prevent-getting-blocked-when-web-scraping
Or use a Powerful Web scraping API like GetOData to get data from any website without getting blocked: