
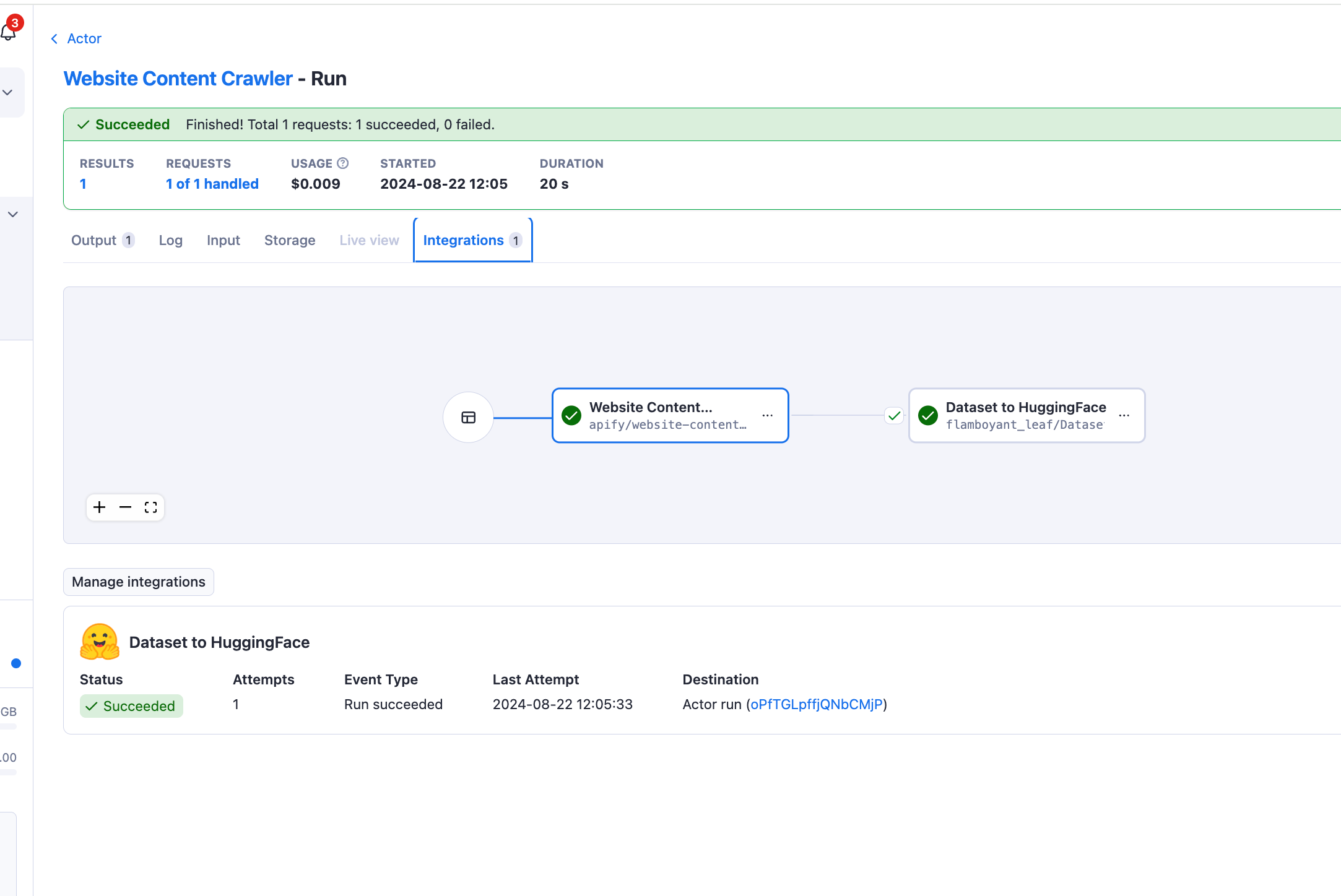
Dataset to HuggingFace
Transfers data from Apify datasets to Hugging Face datasets. Bridges web scraping with ML platforms, enabling access to pre-trained models and collaborative tools. Customize transfer limits, streamline ML workflows, and leverage data versioning. Ideal for data scientists and ML researchers.
Apify to Hugging Face Dataset Transfer
Description
Transfers data from Apify datasets to Hugging Face datasets. Bridges web scraping with ML platforms, enabling access to pre-trained models and collaborative tools. Customize transfer limits, streamline ML workflows, and leverage data versioning. Ideal for data scientists and ML researchers.
What does this actor do?
This actor transfers data from Apify datasets to Hugging Face datasets, bridging Apify's web scraping ecosystem with Hugging Face's machine learning platform.
Key Features
- Transfer data from any Apify dataset to a Hugging Face dataset
- Control the amount of data transferred with customizable limits
- Detailed logging for transparency and debugging
Why transfer data to Hugging Face?
-
Access to State-of-the-Art ML Models: Hugging Face is home to thousands of pre-trained models. Having your data there allows for seamless integration with these models for tasks like sentiment analysis, text classification, or named entity recognition.
-
Collaborative ML Development: Hugging Face provides a collaborative environment where data scientists and researchers can easily share datasets and models. This can be crucial for team projects or open-source contributions.
-
Integration with ML Pipelines: Many ML workflows and tools are designed to work directly with Hugging Face datasets, streamlining your ML pipeline and making it easier to leverage advanced machine learning techniques.
How it works
This actor transfers data from Apify datasets to Hugging Face datasets, preserving the dataset ID. This means your Hugging Face dataset will have the same identifier as your original Apify dataset, making it easy to track and manage your data across platforms.
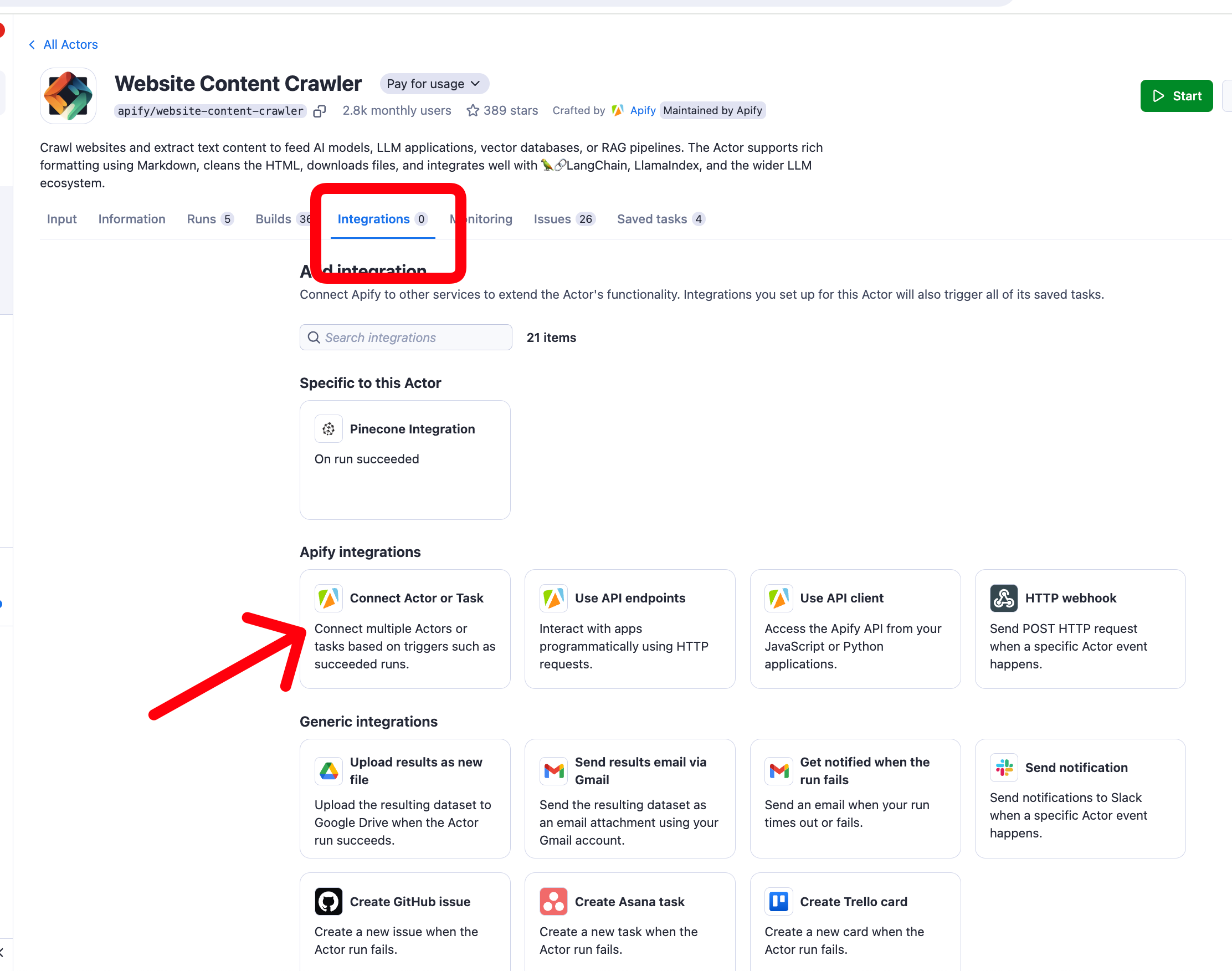
Integration with other actors
The Apify to Hugging Face Dataset Transfer actor can be seamlessly integrated with other Apify actors, such as web scrapers. By using the default dataset ID as input from a previous actor, you can create powerful workflows that automate the entire process from web scraping to machine learning data preparation.
For example, you can:
- Run a web scraper actor to collect data
- Use the default dataset ID from the web scraper as input for this transfer actor
- Automatically transfer the scraped data to Hugging Face
This integration allows for efficient, automated workflows that bridge web scraping and machine learning tasks.
Workflow Animation
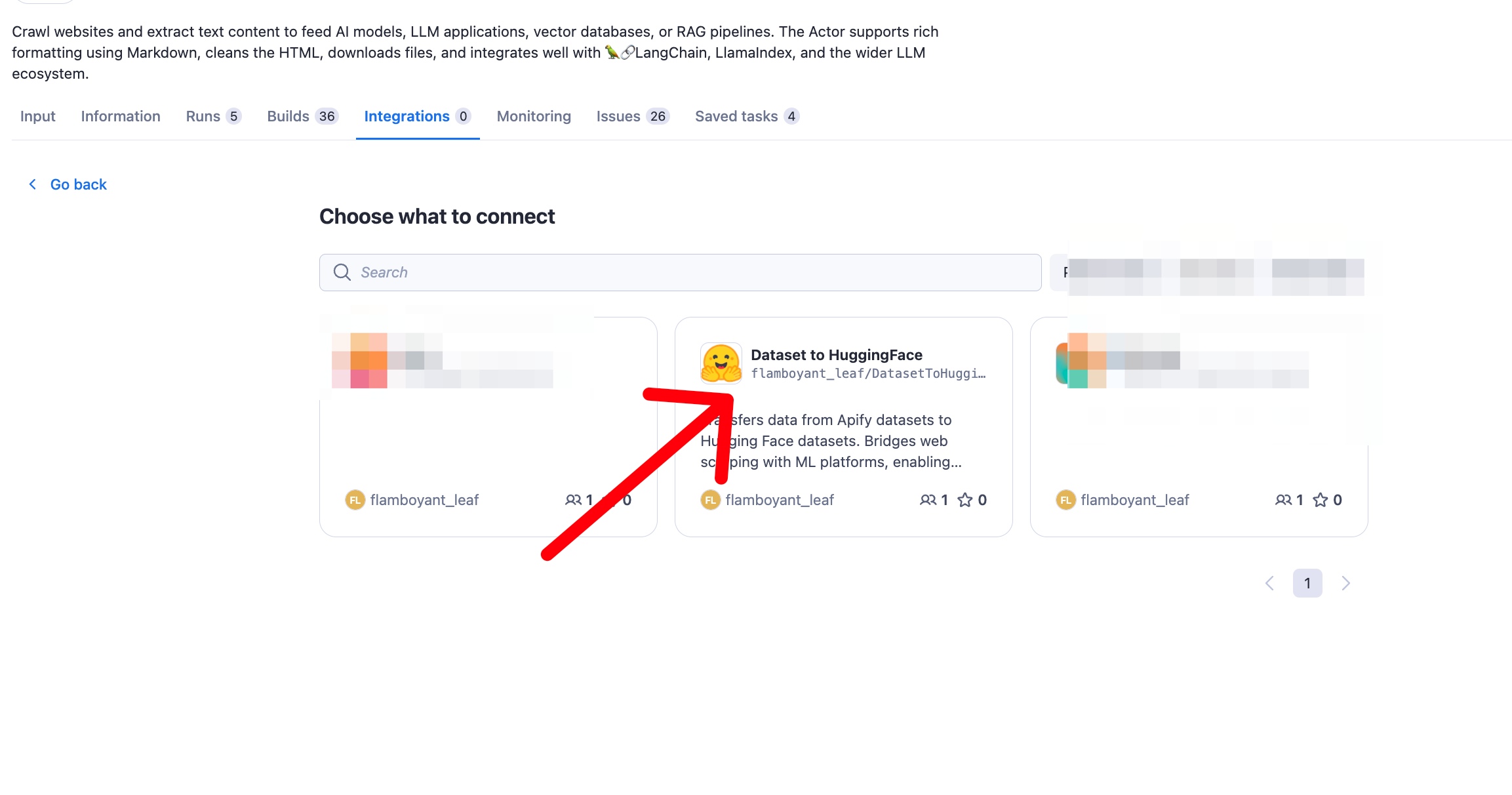
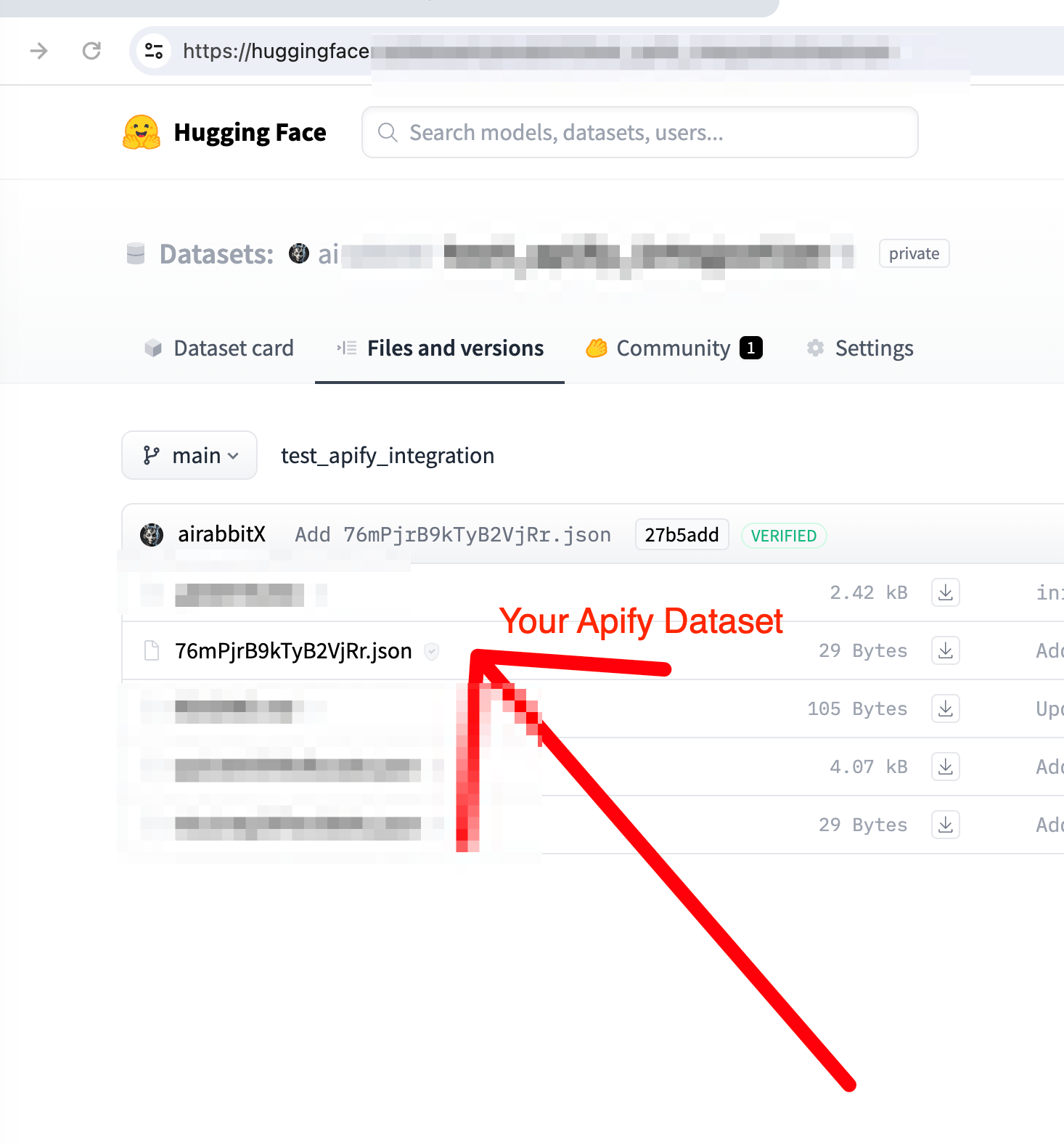
This animation demonstrates how to chain a web scraper actor with the Apify to Hugging Face Dataset Transfer actor, showcasing the seamless flow of data from web sources to a machine learning-ready dataset on Hugging Face.
How to use it
-
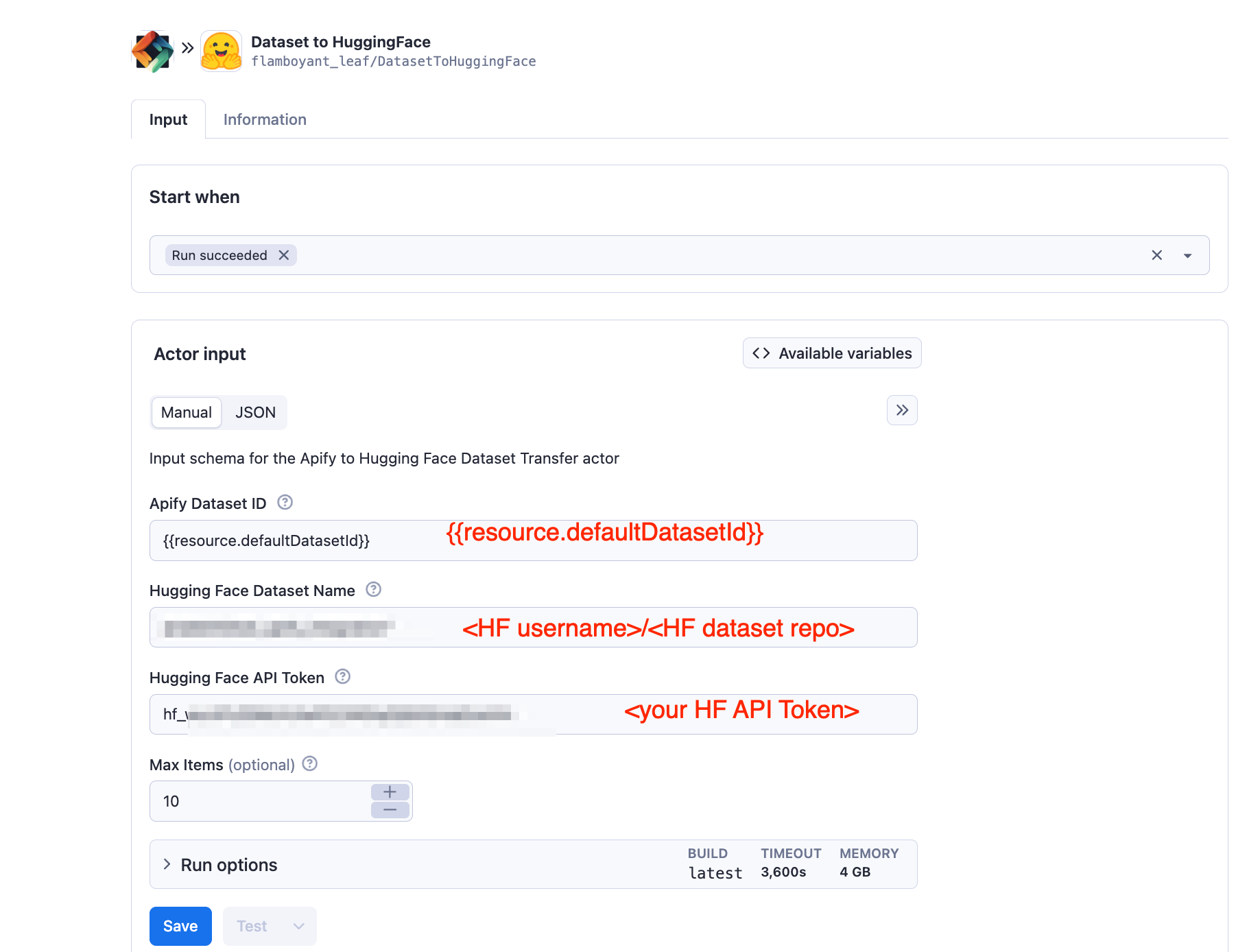
Configure Your Input:
apifyDatasetId: Your Apify dataset IDhuggingFaceDatasetName: Your target Hugging Face dataset namehuggingFaceToken: Your Hugging Face API tokenmaxItems: Maximum number of items to transfer (0 for all items)
-
Run the Actor: Use the Apify platform to run the actor with your input.
-
Access Your Data: Once complete, find your data in the specified Hugging Face dataset.
Input Example
1{ 2 "apifyDatasetId": "your-apify-dataset-id", 3 "huggingFaceDatasetName": "your-huggingface-dataset-name", 4 "huggingFaceToken": "your-huggingface-api-token", 5 "maxItems": 1000 6}
Integrations
Integrate this actor with various services through the Apify platform: Make, Zapier, Slack, Airbyte, GitHub, Google Sheets, Google Drive, and more.
Feedback
We value your input. For suggestions or issues, please create an issue on the actor's GitHub repository or contact Apify support.
Note: Usage of this actor should comply with Apify and Hugging Face terms of service and applicable data protection regulations.
Frequently Asked Questions
Is it legal to scrape job listings or public data?
Yes, if you're scraping publicly available data for personal or internal use. Always review Websute's Terms of Service before large-scale use or redistribution.
Do I need to code to use this scraper?
No. This is a no-code tool — just enter a job title, location, and run the scraper directly from your dashboard or Apify actor page.
What data does it extract?
It extracts job titles, companies, salaries (if available), descriptions, locations, and post dates. You can export all of it to Excel or JSON.
Can I scrape multiple pages or filter by location?
Yes, you can scrape multiple pages and refine by job title, location, keyword, or more depending on the input settings you use.
How do I get started?
You can use the Try Now button on this page to go to the scraper. You’ll be guided to input a search term and get structured results. No setup needed!