
Fast LinkedIn Job Scraper
Extract job listings from Linkedin. Scrape details job details like when it is posted, number of applicants, location and salary range. Download listings data in JSON, XML, Excel.
LinkedIn Job Scraper
Scrape job ads data from LinkedIn easily with LinkedIn Job Scraper.
About
LinkedIn is a business and employment-focused social media platform that works through websites and mobile apps. It was launched on May 5, 2003 by Reid Hoffman and Eric Ly. Since December 2016, LinkedIn has been a wholly owned subsidiary of Microsoft. The platform is primarily used for professional networking and career development, and allows jobseekers to post their CVs and employers to post jobs. From 2015, most of the company's revenue came from selling access to information about its members to recruiters and sales professionals. LinkedIn has more than 1 billion registered members from over 200 countries and territories.
Why should you use it?
It provides the latest job listings from LinkedIn, without requiring login or session cookies, and includes multiple filters to help scrape relevant jobs.
How to use
In order to use LinkedIn Job Scraper you need to provide number of results that you want to scrape from LinkedIn.
It is required to enter keywords by which you would like to search job ads. For example it can be title of job or something that is identifying jobs that you are interested in.
Location parameter is used to filter jobs by their location. Location is not required field.
Examples
Input
Scrape ads with keywords "Java Developer" from New York and scrape maximum of 100 results:
1{ 2 "keywords": "Java Developer", 3 "location": "New York", 4 "maxResults": 100 5}
Scrape job ads added in last 24 hours for keywords "accountant", scrape maximum 10 ads:
1{ 2 "datePosted": "1 day", 3 "keywords": "accountant", 4 "maxRecords": 10 5}
Scrape job ads added in last 12 hours for keywords "accountant", scrape maximum 10 ads. Configuration with hours is only configurable from request, not through UI:
1{ 2 "datePosted": "12 hours", 3 "keywords": "accountant", 4 "maxRecords": 10 5}
How to set time frame through UI?
We can configure it through date posted field. UI component consists from two parts, component for number entering and components for unit entering. Unit can be day, week, month and year. By entering number 1 and unit day, we can configure to get job ads that are add in last 24 hours. If we enter 2 and for unit week, we will get job ads that were added in last two weeks.
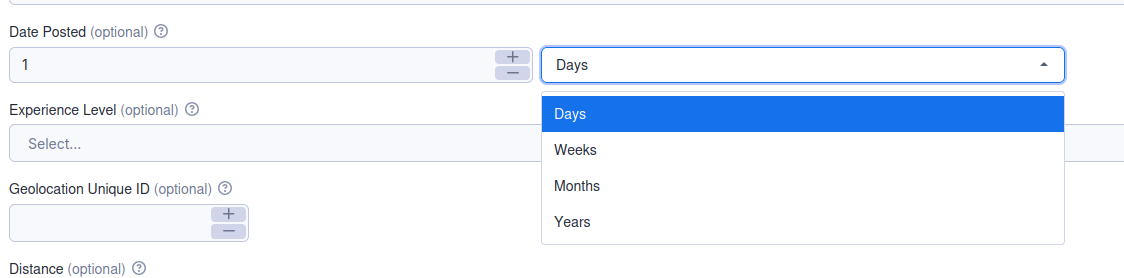
Scrape only jobs with give ids:
1{ 2 "jobIds": ["4083048296", "4083048294"] 3}
In this case job IDs are not counted toward maximum records number. jobIds is basically array of strings for which we would like to get job ads scraped. Can we supply that as file? No, currently Apify input schema is not allowing us to do that. What if we supply keywords parameter or any other input configuration alongside jobIds? All other configuration will be ignored. Scraper will just scrape ads with given IDs.
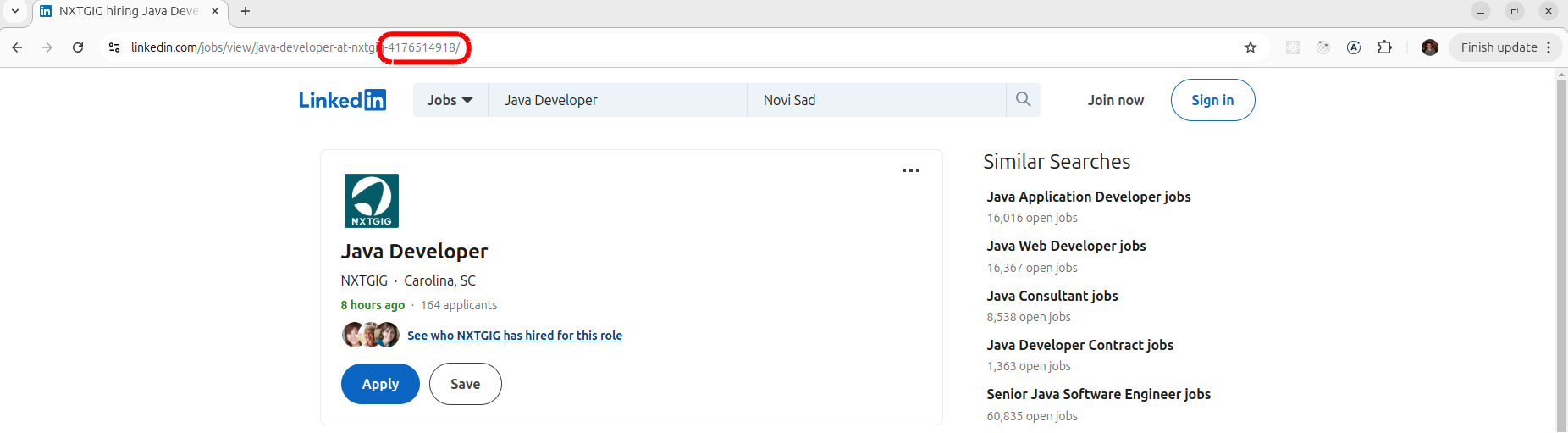
How to find ID?
When you open job ad that you want to scrape you can find ID in ad URL like on picture below:
Output
1{ 2 "id": 4133341026, 3 "url": "https://www.linkedin.com/jobs/view/software-engineer-full-stack-at-paces-4133341026", 4 "title": "Paces hiring Software Engineer (Full-Stack) in New York, NY | LinkedIn", 5 "description": "In the next 30 years, the world will transform every part of the built environment to be climate positive green infrastructure. Knowing what, where, and how to build infrastructure like solar farms is one of the great opportunities of our time. However, there are problems!<br><br><strong>The Problem<br><br></strong>80% of clean energy projects <strong>developers</strong> start never actually get built because most projects are started without deep due diligence on zoning and interconnection due to the cost of collecting that data. This means $17B worth of canceled projects per year.<br><br><strong>Our Solution<br><br></strong>Paces is software for green infrastructure developers to identify the best places to build and manage their projects. First we collect environmental, permitting, zoning, energy grid data from various different sources; then we analyze the data and use AI to identify the best places for developers to build their next projects.<br><br><strong>Our Team<br><br></strong>We are building a team where people can proudly say their time at Paces was the <strong>most impactful, meaningful work of their career.</strong> Our amazing team in Brooklyn, New York includes incredible engineers and growth team members from companies like AWS, Meta AI, Deepmind, Replica, Yotpo, Rent The Runway &amp; Leap.<br><br>Paces is growing rapidly and looking for exceptional people to join who want to have a massive positive climate impact while building a great culture! We are looking for <strong>a scrappy and customer centric full-stack engineer</strong> to join us as we scale up. You will have the chance to build things from ground up and own a large portion of the tech stack.<br><br><strong>🏆 What You’ll Achieve<br><br></strong><ul><li>Lead development on large scale projects, collaborate closely with the product and engineering team</li><li>Optimize speed and scalability of our data heavy platform</li><li>Conduct user researches, iterate with users, improve user experience and identify new opportunities</li><li>Collaborate closely with our CTO and team to directly impact product roadmap<br><br></li></ul>📈 <strong>Requirements<br><br></strong><ul><li>Proficient with React, JavaScript / TypesScript</li><li>Proficient with Python</li><li>You are a proactive and fast learner and able to pick up new things quickly</li><li>You genuinely want to build something people want, enjoy talking to users and learning their needs<br><br></li></ul><strong>✨ About You<br><br></strong>You will thrive in our culture if you:<br><br><ul><li>Have a strong bias towards action and prioritize execution</li><li>Share our passion to build something that fights climate change</li><li>Easily handle the unstructured environment of fast moving startups</li><li>Have the hunger to grow together with Paces as we scale up<br><br></li></ul><strong>🚀 Bonus Points<br><br></strong><ul><li>Previous experience at a high-growth, fast-paced startup</li><li>Previous experience with map frameworks, such as Leaflet.js, Mapbox, and Google Maps</li><li>Previous experience scaling up data intensive, AI and analytics heavy solutions</li><li>Previous experience building and deploying on AWS<br><br></li></ul><strong>💰 Compensation And Benefits<br><br></strong><ul><li>150K - 200K annual compensation</li><li>Competitive equity compensation</li><li>401(k) matching</li><li>Health, Dental and Vision insurance</li><li>Hybrid working in the office 2-4 times per week</li></ul>", 6 "employmentType": "FULL_TIME", 7 "datePosted": "2025-01-24T08:13:55.000Z", 8 "company": { 9 "name": "Paces", 10 "url": "https://www.linkedin.com/company/pacesai", 11 "logo": "https://media.licdn.com/dms/image/v2/D4E0BAQEkl2SXf3S0ag/company-logo_200_200/company-logo_200_200/0/1730398908387/pacesai_logo?e=2147483647&v=beta&t=LOdYxgHkIejq3O91GZEUqU7OmKynZMIWNx7QzPb2G1c", 12 "website": "https://paces.com", 13 "industry": "Software Development", 14 "size": "11-50 employees", 15 "headquarters": "Brooklyn, New York", 16 "type": "Privately Held", 17 "specialities": [], 18 "numberOfEmployees": 73, 19 "numberOfFollowers": 4946, 20 "about": "Paces is a platform that accelerates renewable energy projects by providing comprehensive, real-time insights on permitting, interconnection, and environmental risks. Our platform empowers the entire ecosystem, from renewable energy generation to industrial loads, to make faster, smarter decisions and de-risk projects from origination to development." 21 }, 22 "industry": "Software Development", 23 "location": { 24 "country": "US", 25 "city": "New York", 26 "region": "NY", 27 "address": null, 28 "longitude": -74.00723, 29 "latitude": 40.713047 30 }, 31 "skills": "", 32 "shortTitle": "Software Engineer (Full-Stack)", 33 "validThrough": "2025-05-16T01:21:21.000Z", 34 "applicants": 200, 35 "function": "Engineering and Information Technology", 36 "seniorityLevel": "Entry level", 37 "benefits": [], 38 "salary": "$150,000.00/yr - $200,000.00/yr", 39 "baseSalary": { 40 "currency": "USD", 41 "unit": "YEAR", 42 "min": 150000, 43 "max": 200000 44 }, 45 "educationRequirements": "bachelor degree", 46 "applyUrl": "https://www.ycombinator.com/companies/paces/jobs/Kpdohj0-software-engineer-full-stack?utm_source=syn_li", 47 "isClosed": false, 48 "isAcceptingApplications": true 49}
LinkedIn Job Scraper data output
The output from LinkedIn Job Scraper is stored in the dataset. After the run is finished, you can download the dataset in various data formats (JSON, CSV, XML, RSS, HTML Table).
❓FAQ
Do I need proxies to scrape job ads from LinkedIn?
Proxy for this scraper is already preconfigured for optimal performance.
Support
For more custom/simplify outputs or Bug report please contact the developer (ivan.vasiljevic (at) hotmail.com) or report an issue.
Frequently Asked Questions
Is it legal to scrape job listings or public data?
Yes, if you're scraping publicly available data for personal or internal use. Always review Websute's Terms of Service before large-scale use or redistribution.
Do I need to code to use this scraper?
No. This is a no-code tool — just enter a job title, location, and run the scraper directly from your dashboard or Apify actor page.
What data does it extract?
It extracts job titles, companies, salaries (if available), descriptions, locations, and post dates. You can export all of it to Excel or JSON.
Can I scrape multiple pages or filter by location?
Yes, you can scrape multiple pages and refine by job title, location, keyword, or more depending on the input settings you use.
How do I get started?
You can use the Try Now button on this page to go to the scraper. You’ll be guided to input a search term and get structured results. No setup needed!