
Opensea Collection Activity Scraper
A super advanced Opensea collection activity/events scraper capable of fetching 1000 events in under 5 seconds using $0, with pagination and more!
What does the Opensea Collection Activity/Event Scraper do?
Our Opensea Collection Activity/Events scraper lets you quickly monitor / index events on the Opensea marketplace. This unofficial Opensea API, is super efficient at scraping data for you and costs you near to nothing while being able to fetch you THOUSANDS events in a few seconds. This scraper, fetches all sale, listing, transfer and offer events on an Opensea collection. This is very useful for monitoring trends on collections, and or indexing to create complex datasets for trading or just data analysis in general.
Features
- Scrape all events - listings, sales, transfers, offers (collection, traits, induvidual offers)
- Pagination/Cursor (You have the whole Opensea database at your expenditure, go back as far as 2018 if you need to)
- Impeccable speed + lowest costs you will ever find (refer to the benchmark below)
- Uncached data - All data is updated and bypasses Opensea's caching mechanisms
- Clean and easy to use JSON responses
- Intiuitive Inputs, configure what type of events to scrape, and how many events you want to scrape as well as pagination + proxy support
- Well documented + tutorial
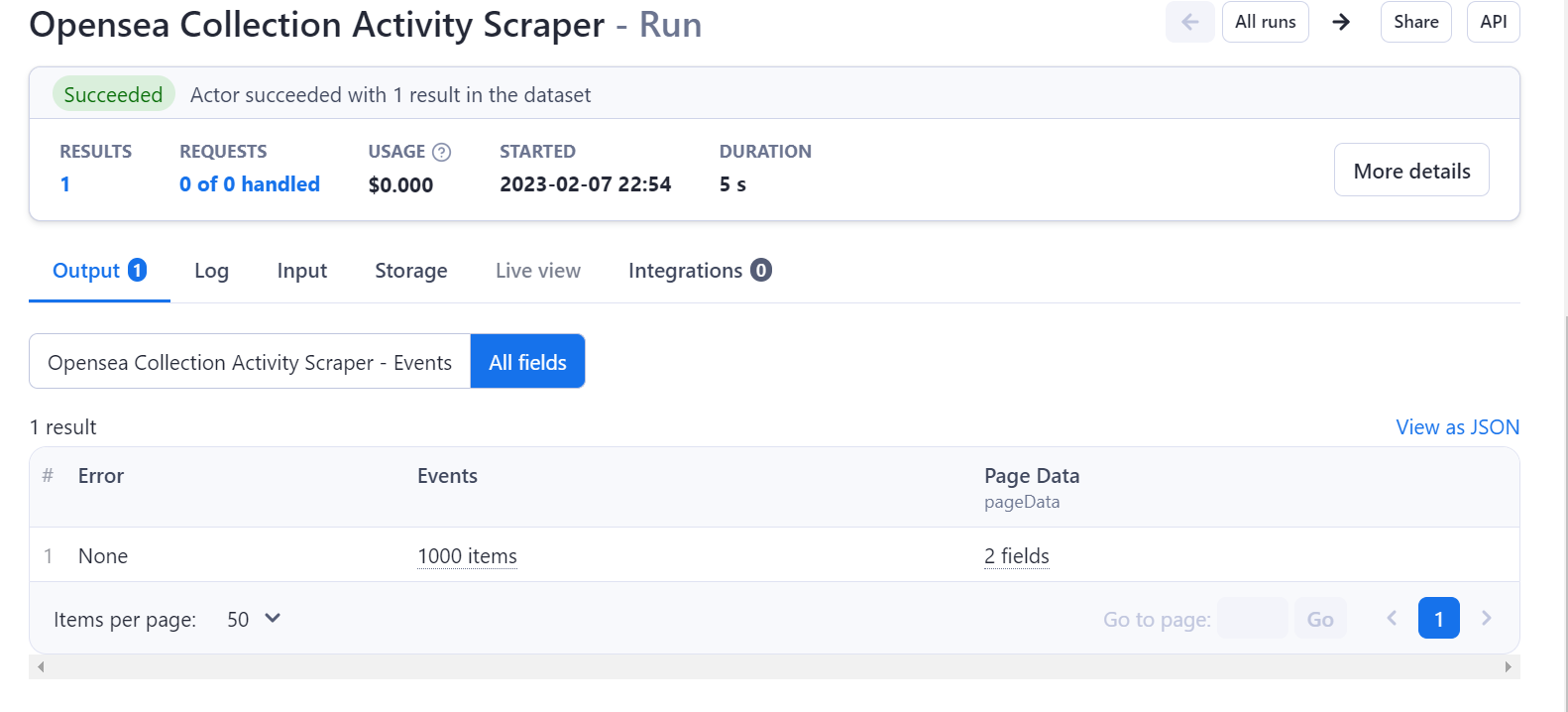
Benchmark (How much does it cost + Speed)
You can scrape a 1000 events in around 5 seconds, using aproximately 0.0004 computing credits which is $0 according to Apify. Dont belive us? Refer to the screen shot below. This scraper makes widescale data collection accessible to all.
Tutorial + Documentation (How to use this scraper)
Github tutorial / documnetation (includes examples): https://github.com/ArgusAPI/opensea-collection-activity-scraper/
Video tutorial coming soon.
For extra support join our discord here
How to use event data from Opensea
- Get new listings which are fat fingered or are under floor price
- Monitor new events and find upcoming market trends
- Index all collection activity and create complex datasets
- Analyse trends from different users and wallets
- Detect collections with fake volume (botted collections with fake volume)
Input parameters
1{ 2 "collectionURL": "https://opensea.io/collection/clonex", 3 "scrapeEventCount": 100, 4 "scrapeEventTypeAuctionCreated": false, 5 "scrapeEventTypeAuctionSuccess": false, 6 "scrapeEventTypeCollectionOffer": false, 7 "scrapeEventTypeOffer": true, 8 "scrapeEventTypeTransfer": false 9}
For more information read our github, mentioned in the tutorial/documentation section
Is it legal to use this scraper?
Yes, scraping public data is legal.
Ouput / Response
You will get a dataset containing the output of this actor. The length of the dataset will depend on the amount of results you've set/got. You can download those results as an Excel, HTML, XML, JSON, and CSV document. The recommended output is JSON, but any export will work fine.
Here's an example of scraped Opensea Collection Event data you'll get if you decide to scrape 1 events from the collection "boredapeyatchclub" (This is only 1 event, but you can scrape hundreds of thousands).
We recommend reading the documentation on what different keys and values in responses mean, but it should be pretty explanatory. Note that different event types have different responses.
1[ 2 { 3 "events": [ 4 { 5 "eventType": "trait_offer", 6 "eventTimestamp": "2023-02-07T22:40:03.677149", 7 "offerEventData": { 8 "fromAccount": { 9 "address": "0x5705b71c9581208fbab754562447185b6895f3ac", 10 "username": "3ArabsCapital", 11 "id": "VXNlclR5cGU6Mzk3ODg5NzQ=", 12 "isCompromised": false 13 }, 14 "payment": { 15 "priceFormatted": "65.00001 WETH", 16 "price": "65.00001", 17 "symbol": "WETH", 18 "ethValue": "65.00001", 19 "usdValue": "108170.41664160000533000082", 20 "quantity": "1" 21 }, 22 "traitCriteria": { 23 "traitType": "Eyes", 24 "traitTypeValue": "Blue Beams" 25 } 26 } 27 } 28 ], 29 "pageData": { 30 "lastCursor": "YXJyYXljb25uZWN0aW9uOmV2ZW50X3RpbWVzdGFtcD1sdDoyMDIzLTAyLTA3IDIyOjQwOjAzLjY3NzE0OSZldmVudF90eXBlPWx0OnRyYWl0X29mZmVyJnBrPWx0Ojk4Mjc0NzE4MTE=", 31 "hasNextPage": true 32 }, 33 "error": "None" 34 } 35]
Refer to the documentation on github for a more documentation on the different responses.
Proxies
The scraper works fine without proxies, though there is a chance you can get ratelimited if running concurrent requests.
For more information view: https://docs.apify.com/proxy
Integrations
The Opensea Collection Activity Scraper can be connected with almost any cloud service or web app thanks to integrations on the Apify platform. You can integrate with Make, Zapier, Slack, Airbyte, GitHub, Google Sheets, Google Drive, and more. Or you can use webhooks to carry out an action whenever an event occurs, e.g. get a notification whenever a new listing is created on a certain collection.
Using scraper with ApifyAPI
The Apify API gives you programmatic access to the Apify platform. The API is organized around RESTful HTTP endpoints that enable you to manage, schedule, and run Apify actors. The API also lets you access any datasets, monitor actor performance, fetch results, create and update versions, and more.
To access the API using Node.js, use the apify-client NPM package. To access the API using Python, use the apify-client PyPI package.
Check out the Apify API reference docs for full details or click on the API tab for code examples.
Feedback / Support / Community
We recommend joining our discord to stay updated with our new products or if you need support. Click here to join
Frequently Asked Questions
Is it legal to scrape job listings or public data?
Yes, if you're scraping publicly available data for personal or internal use. Always review Websute's Terms of Service before large-scale use or redistribution.
Do I need to code to use this scraper?
No. This is a no-code tool — just enter a job title, location, and run the scraper directly from your dashboard or Apify actor page.
What data does it extract?
It extracts job titles, companies, salaries (if available), descriptions, locations, and post dates. You can export all of it to Excel or JSON.
Can I scrape multiple pages or filter by location?
Yes, you can scrape multiple pages and refine by job title, location, keyword, or more depending on the input settings you use.
How do I get started?
You can use the Try Now button on this page to go to the scraper. You’ll be guided to input a search term and get structured results. No setup needed!