
Patreon Scraper 2.0 🎯
🎯 Scrape Patreon.com
Welcome To Patreon Scraper

🎯 About Patreon.com

Patreon (/ˈpeɪtriɒn/, /-ən/) is a membership platform that provides business tools for content creators to run a subscription service. It helps creators and artists earn a monthly income by providing rewards and perks to their subscribers. Patreon charges a commission of 9 to 12 percent of creators' monthly income, in addition to payment processing fees.
🎯 About This Actor
All-In-One Patreon.com Scraper
Features :
- ⭐ Scrape creator info
- ⭐ Scrape campaign info, collection, products, chats, etc.
- ⭐ Scrape & search posts
- ⭐ Scrape comments
- ⭐ Accept
URLinputs - ⭐ Multiple
queryin single request - ⭐ Scrape personal data (session cookie required
session_id)
Disclaimer :
- 📝 On Free Trial,
queryis limited to 5 per request. - 📝 On Free Trial, results is limited to first 100 results.
🎯 Tutorial
Patreon Query Language (PQL)
[ <COMMAND>: | # | @ ] [ <NAME> | <ID> | <KEYWORD> | <URL> ] [ /<SECTION> ]
Possible Query Values
| Format | Examples | Description |
|---|---|---|
| <KEYWORDS> | AI arts | Search Creators / Campaign |
| @<CAMPAIGN_ID> | @666522 | Campaign Data |
| @<CAMPAIGN_NAME> | @TheBestShow | |
/info | @TheBestShow/info | Campaign info |
/posts | @TheBestShow/posts | Campaign posts |
/collections | @TheBestShow/collections | Campaign collections |
/products | @TheBestShow/products | Campaign products (shop) |
/chats | ||
| user:<USER_ID> | user:4696495 | Creator/User Data |
/info | user:4696495/info | Creator info |
| <POST_ID> | 100277166 | Post Data |
/info | 100277166/info | Post content |
/comments | 100277166/comments | Post comments |
/related | 100277166/related | Related posts |
| collection:<COLLECTION_ID> | collection:12345678 | Collection Data |
/info | collection:12345678/info | Collection info |
/posts | collection:12345678/posts | Collection post |
| product:<PRODUCT_ID> | product:12345678 | Product Data |
/info | product:12345678/info | Product info |
| home:<SECTION> | home:info | Personal Data |
:info | home:info | User info |
:updates | home:updates | Feed updates |
:notifications | home:notifications | Notifications |
| https:<URL> | https://www.patreon.com/... | Start URL |
/<CAMPAIGN> | @<CAMPAIGN> | |
/<CAMPAIGN>/shop | @<CAMPAIGN>/products | |
/<CAMPAIGN>/collections | @<CAMPAIGN>/collections | |
/posts/title-slug-<POST_ID> | <POST_ID> |
🎯 Input Examples
Example #1: Scrape a Post
{ "query": ["https://www.patreon.com/posts/post-title-slug-3001122"] }
or
{ "query": ["3001122"] } # just input the POST_ID
Example #2: Scrape a Post Comments
{ "query": ["3001122/comments"] }
🎯 LOGIN SESSION
You may want to include your login session from your browser. If that's the case, you need to include the cookie named session_id. To get the cookie value, follow these steps :
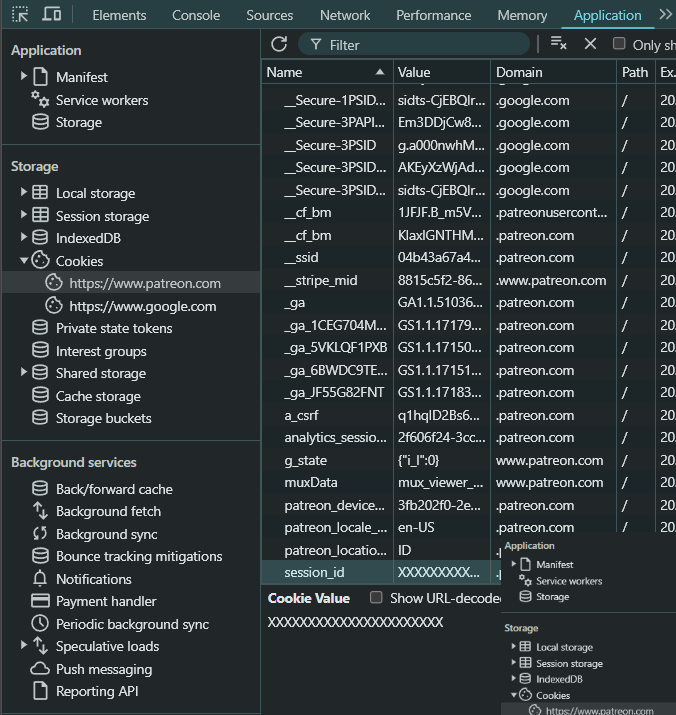
Google Chrome
- Login to patreon.com
- Open Chrome Developer Tools
(Ctrl + Shift + I) - Open Application Tab
- On left panel, go to:
Storage -> Cookies -> https://www.patreon.com - Find cookie named
session_id - Copy & Paste
🎯 Output Examples
1{ 2 "access_rules": [ 3 { 4 "access_rule_type": "tier", 5 "amount_cents": null, 6 "currency": "USD", 7 "id": "7909551", 8 "post_count": 603, 9 "type": "access-rule" 10 }, 11 { 12 "access_rule_type": "tier", 13 "amount_cents": null, 14 "currency": "USD", 15 "id": "9059915", 16 "post_count": 337, 17 "type": "access-rule" 18 } 19 ], 20 "audio": { 21 "file_name": "AdFree-DraftV1-20221007-TCO-Hillsong1.mp3", 22 "id": "171203911", 23 "image_urls": null, 24 "metadata": {}, 25 "type": "media" 26 }, 27 "change_visibility_at": null, 28 "comment_count": 56, 29 "commenter_count": 34, 30 "current_user_can_comment": false, 31 "current_user_can_delete": false, 32 "current_user_can_view": false, 33 "has_ti_violation": false, 34 "id": "72996515", 35 "image": { 36 "height": 480, 37 "large_url": "https://c10.patreonusercontent.com/4/patreon-media/p/campaign/1508621/d2bfcfd4a278419abad6926b2155d514/eyJoIjozNDksInciOjYyMH0%3D/3?token-time=2145916800&token-hash=b3gTD8SkGyerTsc2f5mkx7NeQhl0lhl7qj_bihrza9I%3D", 38 "thumb_square_large_url": "https://c10.patreonusercontent.com/4/patreon-media/p/campaign/1508621/d2bfcfd4a278419abad6926b2155d514/eyJoIjozNDksInciOjYyMH0%3D/3?token-time=2145916800&token-hash=b3gTD8SkGyerTsc2f5mkx7NeQhl0lhl7qj_bihrza9I%3D", 39 "thumb_square_url": "https://c10.patreonusercontent.com/4/patreon-media/p/campaign/1508621/d2bfcfd4a278419abad6926b2155d514/eyJoIjozNDksInciOjYyMH0%3D/3?token-time=2145916800&token-hash=b3gTD8SkGyerTsc2f5mkx7NeQhl0lhl7qj_bihrza9I%3D", 40 "thumb_url": "https://c10.patreonusercontent.com/4/patreon-media/p/campaign/1508621/d2bfcfd4a278419abad6926b2155d514/eyJoIjozNDksInciOjYyMH0%3D/3?token-time=2145916800&token-hash=b3gTD8SkGyerTsc2f5mkx7NeQhl0lhl7qj_bihrza9I%3D", 41 "url": "https://c10.patreonusercontent.com/4/patreon-media/p/campaign/1508621/d2bfcfd4a278419abad6926b2155d514/eyJoIjozNDksInciOjYyMH0%3D/3?token-time=2145916800&token-hash=b3gTD8SkGyerTsc2f5mkx7NeQhl0lhl7qj_bihrza9I%3D", 42 "width": 640 43 }, 44 "images": [], 45 "insights_last_updated_at": "2022-10-11T05:36:00.659+00:00", 46 "is_paid": false, 47 "like_count": 188, 48 "media": [ 49 { 50 "file_name": "AdFree-DraftV1-20221007-TCO-Hillsong1.mp3", 51 "id": "171203911", 52 "image_urls": null, 53 "metadata": {}, 54 "type": "media" 55 } 56 ], 57 "meta_image_url": "https://c7.patreon.com/https%3A%2F%2Fwww.patreon.com%2F%2Fpost-teaser-image%2F72996515/selector/%23post-teaser", 58 "min_cents_pledged_to_view": null, 59 "moderation_status": "not_being_reviewed", 60 "native_video_insights": null, 61 "patreon_url": "https://www.patreon.com/posts/hillsong-exposed-72996515", 62 "pledge_url": "/bePatron?patAmt=5.0&c=1508621", 63 "pls_one_liners_by_category": [], 64 "poll": null, 65 "post_level_suspension_removal_date": null, 66 "post_metadata": null, 67 "post_type": "audio_file", 68 "preview_asset_type": "default", 69 "published_at": "2022-10-07T10:08:07.000+00:00", 70 "teaser_text": "In the early 2000s a new kind of church appeared in New York City. It wasn't \"regular\" church, it was \"cool\" church. It was a church with ce", 71 "ti_checks": [], 72 "title": "Hillsong: A MegaChurch Exposed. Ep 1: Welcome Home", 73 "type": "post", 74 "upgrade_url": "/join/TrueCrimeObsessed/checkout?rid=2334613", 75 "url": "https://www.patreon.com/posts/hillsong-exposed-72996515", 76 "user_defined_tags": [], 77 "video_preview": null, 78 "view_count": 467, 79 "was_posted_by_campaign_owner": true 80}
Frequently Asked Questions
Is it legal to scrape job listings or public data?
Yes, if you're scraping publicly available data for personal or internal use. Always review Websute's Terms of Service before large-scale use or redistribution.
Do I need to code to use this scraper?
No. This is a no-code tool — just enter a job title, location, and run the scraper directly from your dashboard or Apify actor page.
What data does it extract?
It extracts job titles, companies, salaries (if available), descriptions, locations, and post dates. You can export all of it to Excel or JSON.
Can I scrape multiple pages or filter by location?
Yes, you can scrape multiple pages and refine by job title, location, keyword, or more depending on the input settings you use.
How do I get started?
You can use the Try Now button on this page to go to the scraper. You’ll be guided to input a search term and get structured results. No setup needed!