
Pornhub Data Extractor
Unofficial Pornhub API to extract videos, actors, channels, and category data. Get direct video URLs, thumbnails, views, ratings, tags, and more. Perfect for content research, SEO, or automation. Export structured data for use in apps, reports, or dashboards.
Pornhub Extractor 🤖
⚠️ AGE RESTRICTION NOTICE
This tool interacts with an adult content platform that contains explicit material. By using this actor, you confirm that:
- You are at least 18 years of age (or the legal age of majority in your jurisdiction)
- You are legally permitted to access adult content in your location
- You understand and accept the nature of the content being processed
This actor is intended for legitimate research, analysis, and content management purposes only. Please ensure compliance with all applicable laws and regulations in your jurisdiction.
🚀 React Native Demo
Dornhub Demo - A Pornhub analytics app built with Apify actors and Gemini AI.
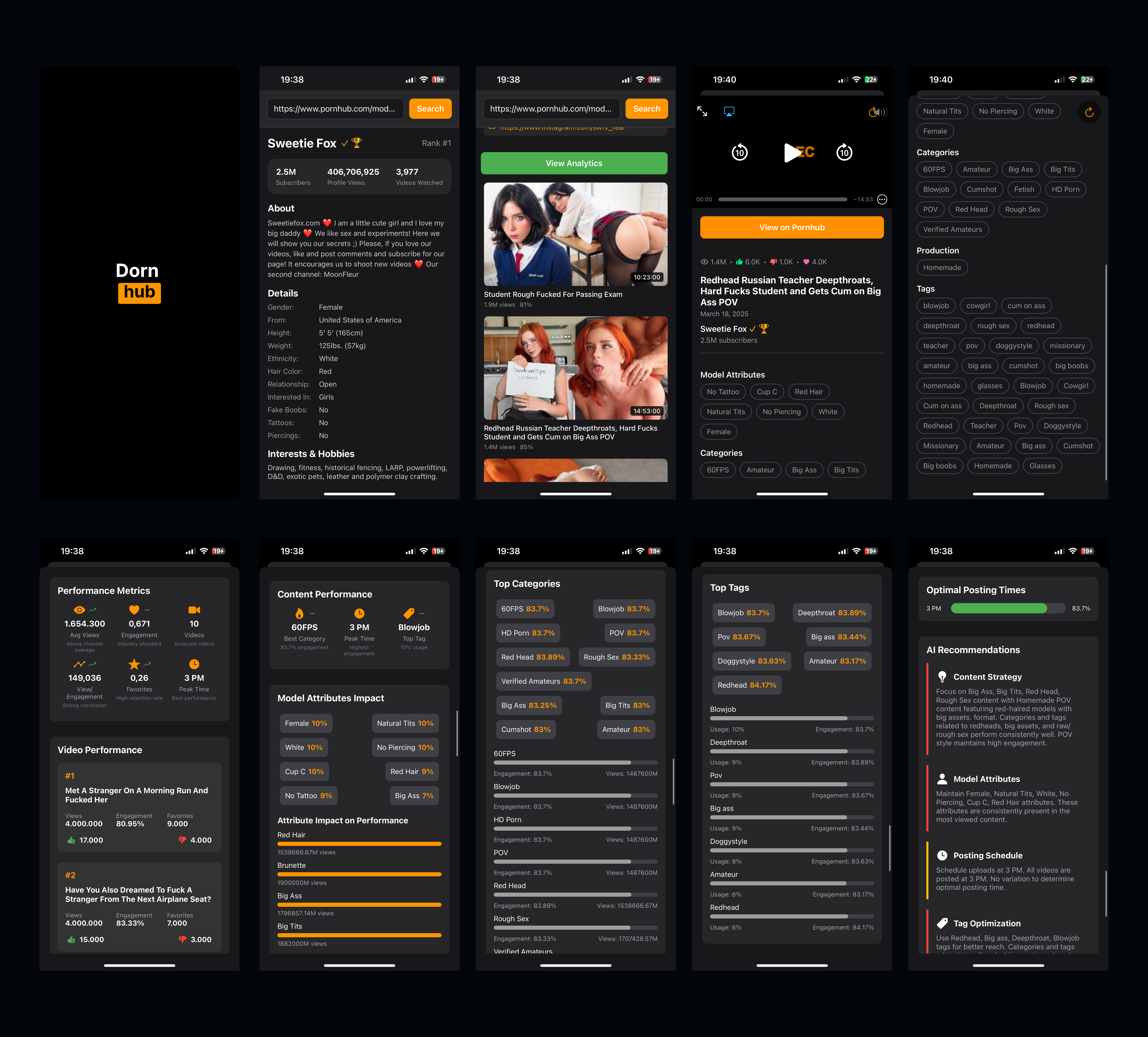
This demo app showcases how you can:
- Build a powerful analytics dashboard using Apify's Pornhub actors
- Leverage AI (Gemini) for content analysis and recommendations
🎯 Business Value
For Content Creators & Models
- Performance Analytics: Track video metrics to optimize content strategy
- AI-Powered Insights: Get recommendations for content and posting schedules
- Competitive Analysis: Compare performance across categories and tags
For Platform Managers & Agencies
- Model Portfolio Management: Monitor multiple models in one dashboard
- Content Strategy: Use AI insights to guide content creation
- ROI Tracking: Measure engagement and conversion metrics
Perfect example of how the structured, ready-to-use data provided by Apify's Pornhub actors (like this Extractor!) accelerates development and enables insightful applications for content creators and platform managers.
About Pornhub Extractor
Pornhub Extractor is a powerful web scraping solution that extracts structured data from Pornhub.com. It provides comprehensive video and channel metadata that you can use for research, analysis, and content management.
🔎 What Does Pornhub Extractor Do?
This actor navigates through Pornhub.com to collect detailed information about videos, channels, actors, and categories. It allows you to extract:
- Video titles and metadata
- View counts and ratings
- Duration and upload dates
- Model/uploader information
- Thumbnail URLs and video links
- Search results based on keywords
- Channel information including subscribers and video counts
- Channel rankings and statistics
- Actor profiles with verification status and awards
- Category listings with video counts
You can download this structured data in JSON, CSV, Excel, or HTML formats for analysis, integration, or business insights.
✨ Key Features
- ✅ Complete data extraction - Get comprehensive video and channel metadata
- ✅ Search functionality - Filter results using specific keywords (e.g., 'Lana Rhoades', 'Kriss Kiss')
- ✅ Category filtering - Filter results by specific categories (e.g., 'Amateur', 'Pornstar', 'Verified Amateurs')
- ✅ Flexible pagination - Control which pages to scrape with start and end page numbers
- ✅ Channel analytics - Extract subscriber counts, video views, and rankings
- ✅ Customizable parameters - Configure the scraper to get exactly the data you need
- ✅ Dataset naming - Automatically name datasets
- ✅ Regular updates - Constantly maintained to handle website changes
📊 What Data Can You Extract?
Pornhub Extractor provides a comprehensive dataset including:
Video Data/Video Data Search:
- Video ID and URL
- Title and duration
- View count and rating
- Model/uploader name and URL
- Thumbnail URL
Channel Data/Channel Data Search:
- Channel name and URL
- Subscriber count
- Total videos
- Total video views
- Channel rank
- Thumbnail URL
Actor Data:
- Actor name and URL
- Profile image URL
- Rank and verification status
- Award winner status
- Video count and view count
Category Data:
- Category title and URL
- Category image URL
- Video count
📥 How to Use Pornhub Extractor
No coding required! Just follow these steps:
- Open Pornhub Extractor on Apify
- Configure your search (optional) - Set parameters like
search,category, etc. - Configure other inputs (optional) - Use settings like
maxItems,startPage,endPage, etc. - Start the actor - Let it collect the data for you
- Download your data - Export in JSON, CSV, Excel, or HTML
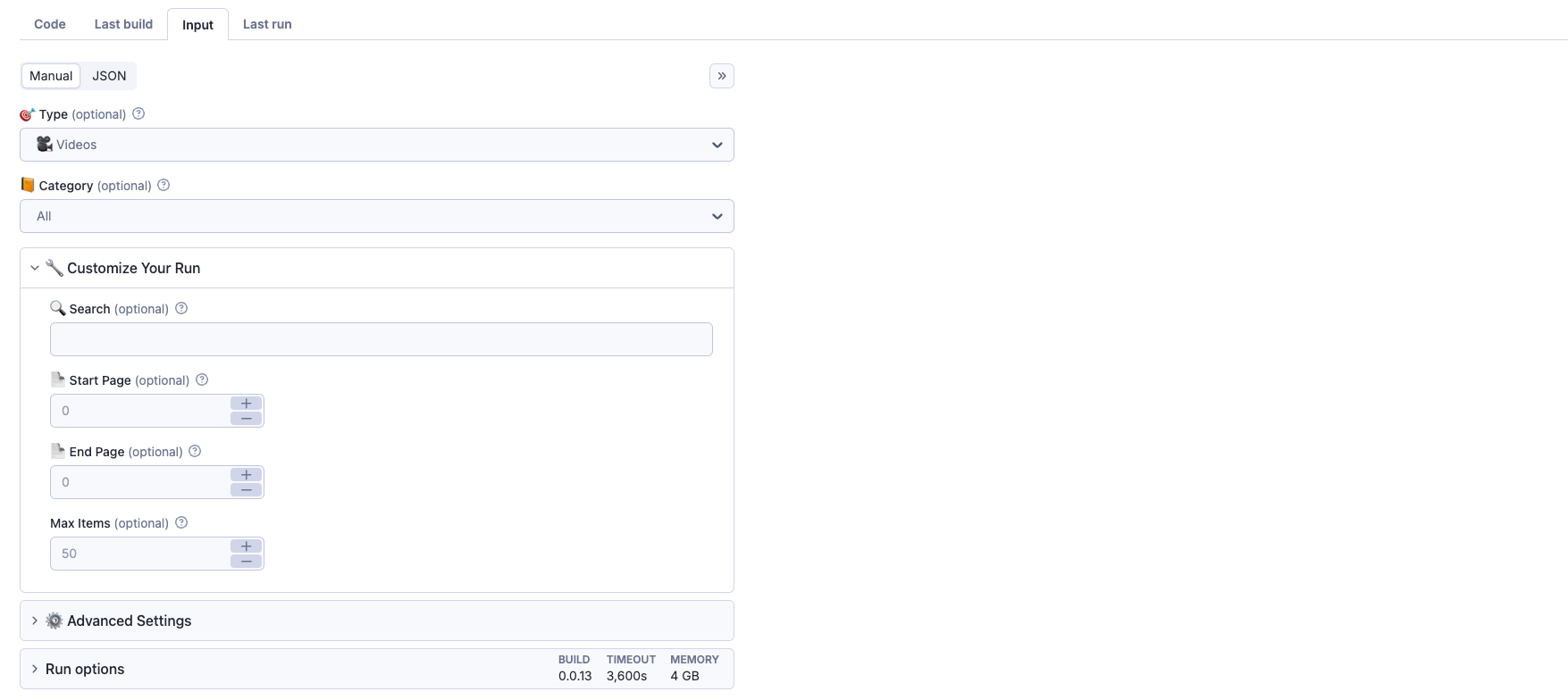
📌 Input Parameters
Customize your data extraction with these parameters:
1{ 2 "type": "VIDEOS", // or "ACTORS", "CHANNELS", "CATEGORIES" 3 "category": "all", // Filter by specific category 4 "search": "Lana Rhoades", // Search for specific content 5 "startPage": 0, // Page number to start scraping from (0 for homepage) 6 "endPage": 0, // Page number to end scraping at (0 means no limit) 7 "maxItems": 50, // Maximum number of items to extract (max: 5000) 8 "nameDataset": false, // Whether to name the dataset 9 "maxRequestsPerCrawl": 50, // Maximum number of requests per run (max: 100) 10 "proxyConfiguration": { 11 "useApifyProxy": true // Use Apify's proxy pool 12 } 13}
- type - Type of data to extract: "VIDEOS", "ACTORS", "CHANNELS", or "CATEGORIES" (default: "VIDEOS")
- category - Filter results by specific category (default: "all"). Available categories include:
- Mature, Teen (18+), MILF, Ebony, Anal, Lesbian, etc.
- Full list available in the actor's input configuration
- search - Enter a keyword to search for specific content (e.g., 'Lana Rhoades', 'Kriss Kiss')
- startPage - Page number to start scraping from (0 for homepage, default: 0)
- endPage - Page number to end scraping at (0 means no limit, default: 0)
- maxItems - Maximum number of items to extract (default: 50, max: 5000)
- nameDataset - Whether to name the dataset (default: false)
- maxRequestsPerCrawl - Maximum number of requests per run (default: 50, max: 100)
- proxyConfiguration - Configure proxy settings for the crawler. By default, it uses Apify's proxy pool to ensure reliable scraping and avoid IP blocks.
📊 Output Data Structure
After extraction, your structured dataset will look like this:
Video Data/Video Data Search:
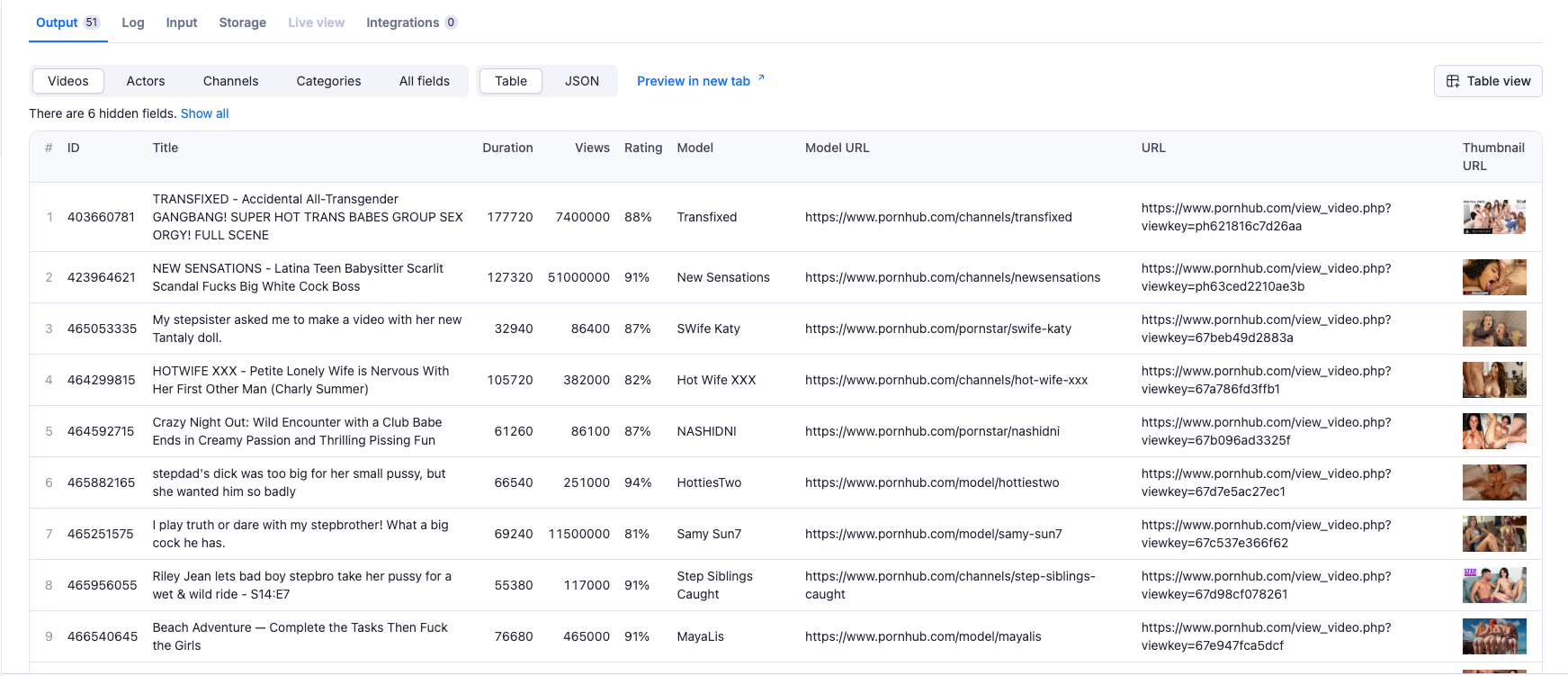
1{ 2 "id": "string", 3 "title": "string", 4 "duration": "number", 5 "views": "number", 6 "rating": "string", 7 "model": "string", 8 "model_url": "string", 9 "url": "string", 10 "thumbnail_url": "string" 11}
Channel Data/Channel Data Search:
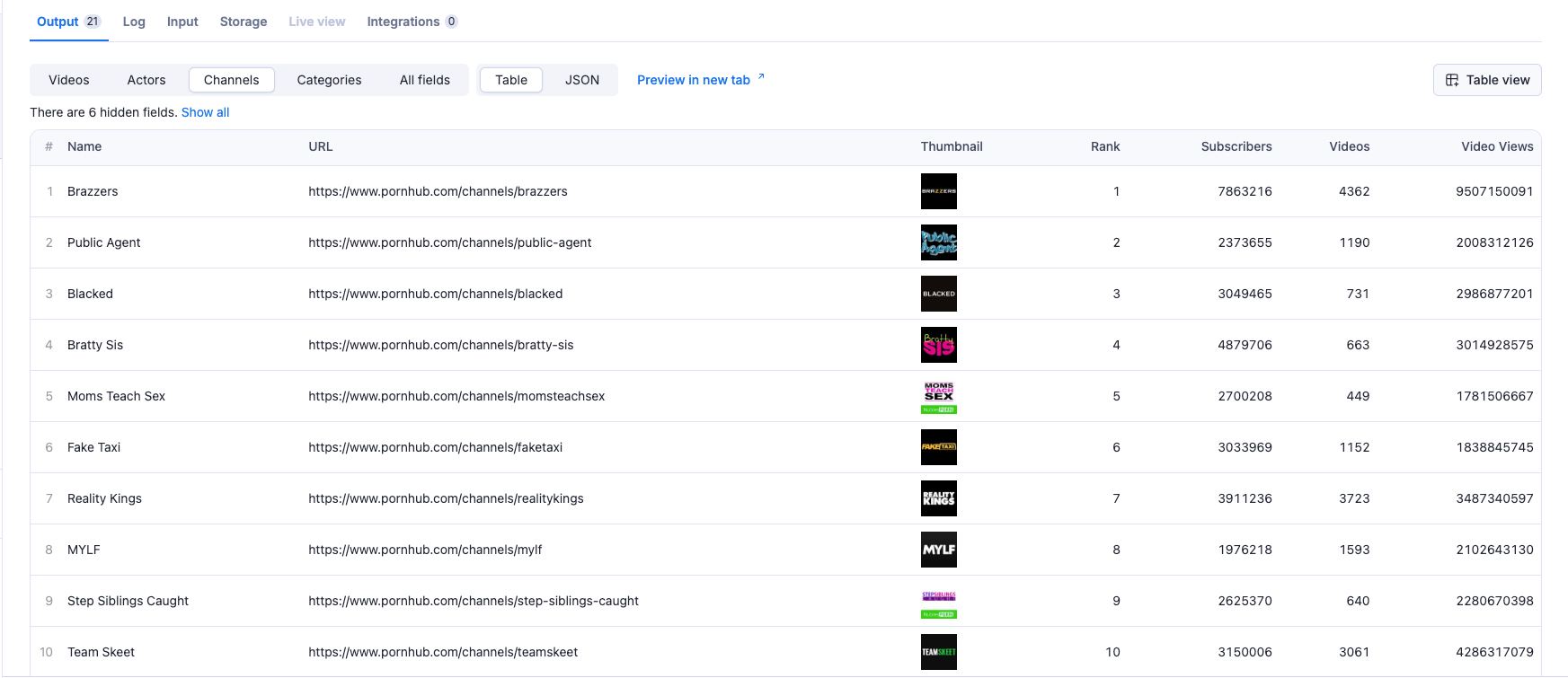
1{ 2 "name": "string", 3 "url": "string", 4 "thumbnail": "string", 5 "rank": "number", 6 "subscribers": "number", 7 "videos": "number", 8 "video_views": "number" 9}
Actor Data:
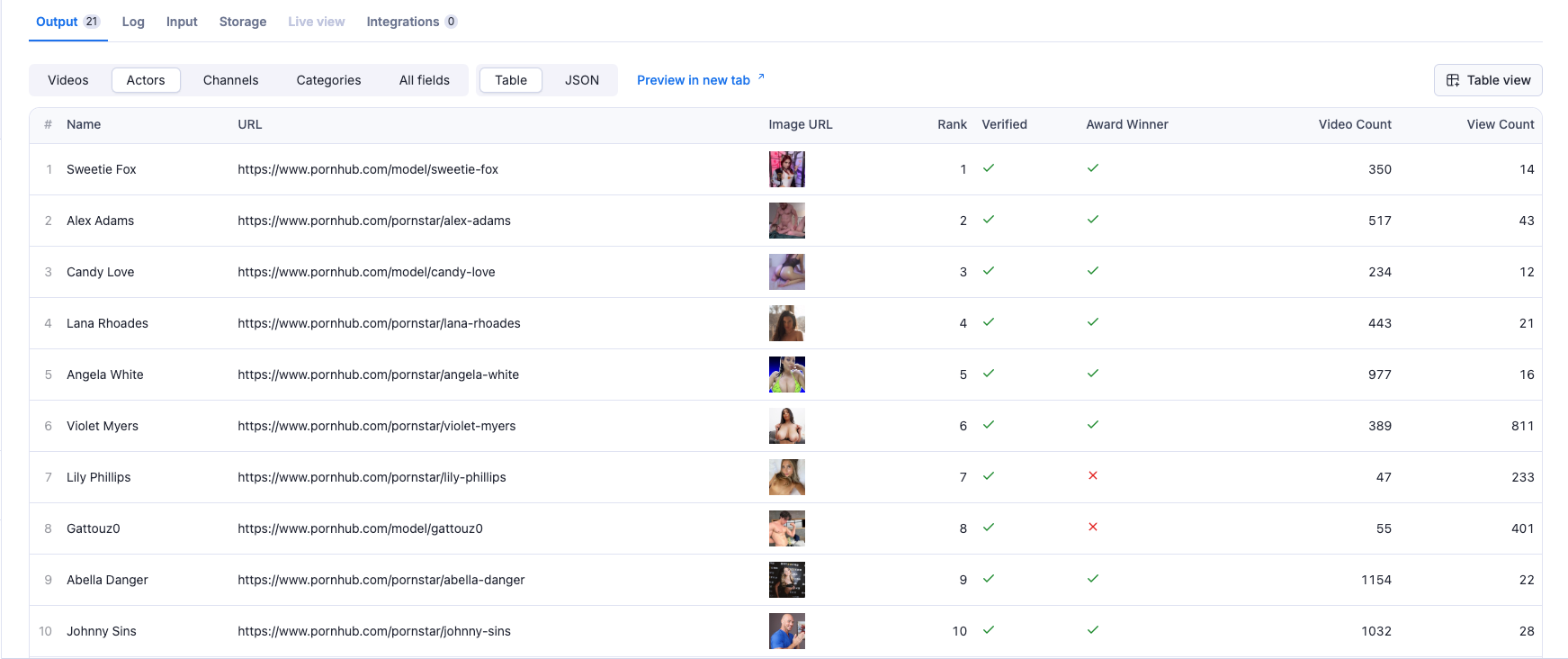
1{ 2 "name": "string", 3 "url": "string", 4 "image_url": "string", 5 "rank": "number", 6 "is_verified": "boolean", 7 "is_award_winner": "boolean", 8 "video_count": "number", 9 "view_count": "number" 10}
Category Data:
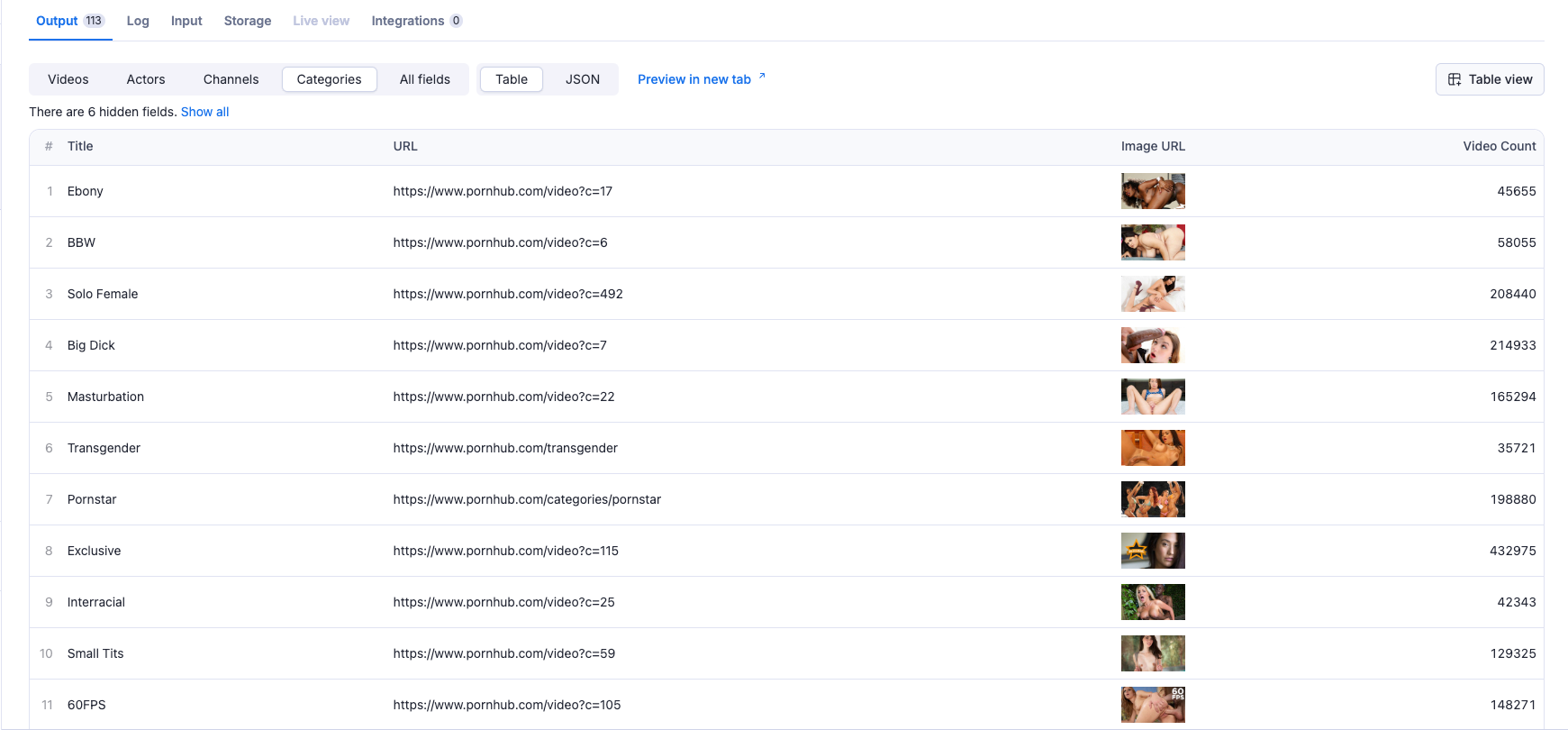
1{ 2 "title": "string", 3 "url": "string", 4 "image_url": "string", 5 "video_count": "number" 6}
📡 Integrations & Automation
Pornhub Extractor can be integrated with multiple platforms, including:
- Make (formerly Integromat)
- Zapier
- Google Drive & Sheets
- Slack & Discord
- Airbyte & GitHub
You can also set up webhooks to trigger automatic actions when new data is extracted!
❓ FAQ
Can I integrate Pornhub Extractor with my own app?
Yes! You can use the Apify API to programmatically run extractions and fetch results in real time.
The Apify API gives you programmatic access to the Apify platform. The API is organized around RESTful HTTP endpoints that enable you to manage, schedule, and run Apify actors. The API also lets you access any datasets, monitor actor performance, fetch results, create and update versions, and more.
To access the API using Node.js, use the apify-client NPM package. To access the API using Python, use the apify-client PyPI package.
Is it legal to scrape Pornhub?
Our Pornhub Extractor is designed to be ethical and compliant, ensuring that it does not extract any private user data, such as email addresses or other personally sensitive information. It can only collect publicly available data that companies have chosen to share.
Personal data is protected under GDPR in the European Union and similar laws worldwide. You should not scrape personal data unless you have a legitimate reason to do so.
If you're unsure whether your reason is legitimate, consult your lawyers. You can also read our blog post on the legality of web scraping and ethical scraping.
🚀 Start Using Pornhub Extractor Today!
- ✅ No coding skills required
- ✅ Try it for free with Apify's free credits
- ✅ Download structured data easily
Related Actors ⭐
- Pornhub Video Extractor (Downloader)
Unofficial Pornhub Scraper to extract video data, tags, views, ratings, categories, performers, channel info, thumbnails, and download URL. Ideal for SEO, content research, competitor tracking, media monitoring, automation, and data-driven insights. Fast, reliable, and no coding needed. - Pornhub Channel Data Extractor
Pornhub Channel Data Extractor is a powerful web scraping solution that extracts data from Pornhub model and pornstar channels. It provides comprehensive, structured data that you can use for content analysis, market research, and data aggregation
Frequently Asked Questions
Is it legal to scrape job listings or public data?
Yes, if you're scraping publicly available data for personal or internal use. Always review Websute's Terms of Service before large-scale use or redistribution.
Do I need to code to use this scraper?
No. This is a no-code tool — just enter a job title, location, and run the scraper directly from your dashboard or Apify actor page.
What data does it extract?
It extracts job titles, companies, salaries (if available), descriptions, locations, and post dates. You can export all of it to Excel or JSON.
Can I scrape multiple pages or filter by location?
Yes, you can scrape multiple pages and refine by job title, location, keyword, or more depending on the input settings you use.
How do I get started?
You can use the Try Now button on this page to go to the scraper. You’ll be guided to input a search term and get structured results. No setup needed!