
Substack Scraper
The Substack Author Scraper is a powerful Apify actor that makes it easy for content creators to scrape and retrieve all posts from their favorite Substack authors. With structured data presented in a user-friendly format, analyzing and processing valuable information has never been easier.
Substack Author Scraper

Substack Author Scraper is an Apify actor designed to scrape all posts from a specified Substack author and retrieve the content of each article. The actor returns the data in a structured format, as a list of dictionaries, making it easy to analyze and process the information further.
Features
- 🔍 Scrape all posts from a specified Substack author.
- 📝 Retrieve each article's content.
- 📋 Results are provided in a structured format (list of dictionaries).
- ⚙️ Customizable options to limit the number of posts and include or exclude article content in the results.
Input
The actor accepts the following input properties:
- 🕵️ Author name: The name of the Substack author whose posts you want to scrape. (Default: "garyvee")
- 🔢 Limit number of posts: The number of posts to retrieve. This will get the latest 'n' posts, where 'n' is the specified limit. (Default: 25)
- 📜 Article content: A boolean flag to include or exclude the parsed article content in the results. (Default: false)
Output
The actor will return a JSON array containing information about each scraped post. Each entry in the array will be a dictionary containing the following keys:
- 📌 title: The title of the post.
- 🔗 url: The URL of the post.
- 👤 author: The author's name.
- 🔗 author_url: The URL of the author's Substack profile.
- 📅 published_at: The publication date and time of the post.
If the "Article content" input property is set to true, each entry will also include the following key:
- 📝 body: A list of content objects representing the structure of the article. Each content object will contain the following keys:
- 📌 content_type: The type of content (e.g., "h" for heading, "p" for paragraph, "img" for image, "a" for link, "hr" for divider).
- 🔗 src: The source URL for images, videos, or links (optional).
- 🆔 level: The heading level for headings (optional).
- 📝 content: The content of headings and paragraphs (optional).
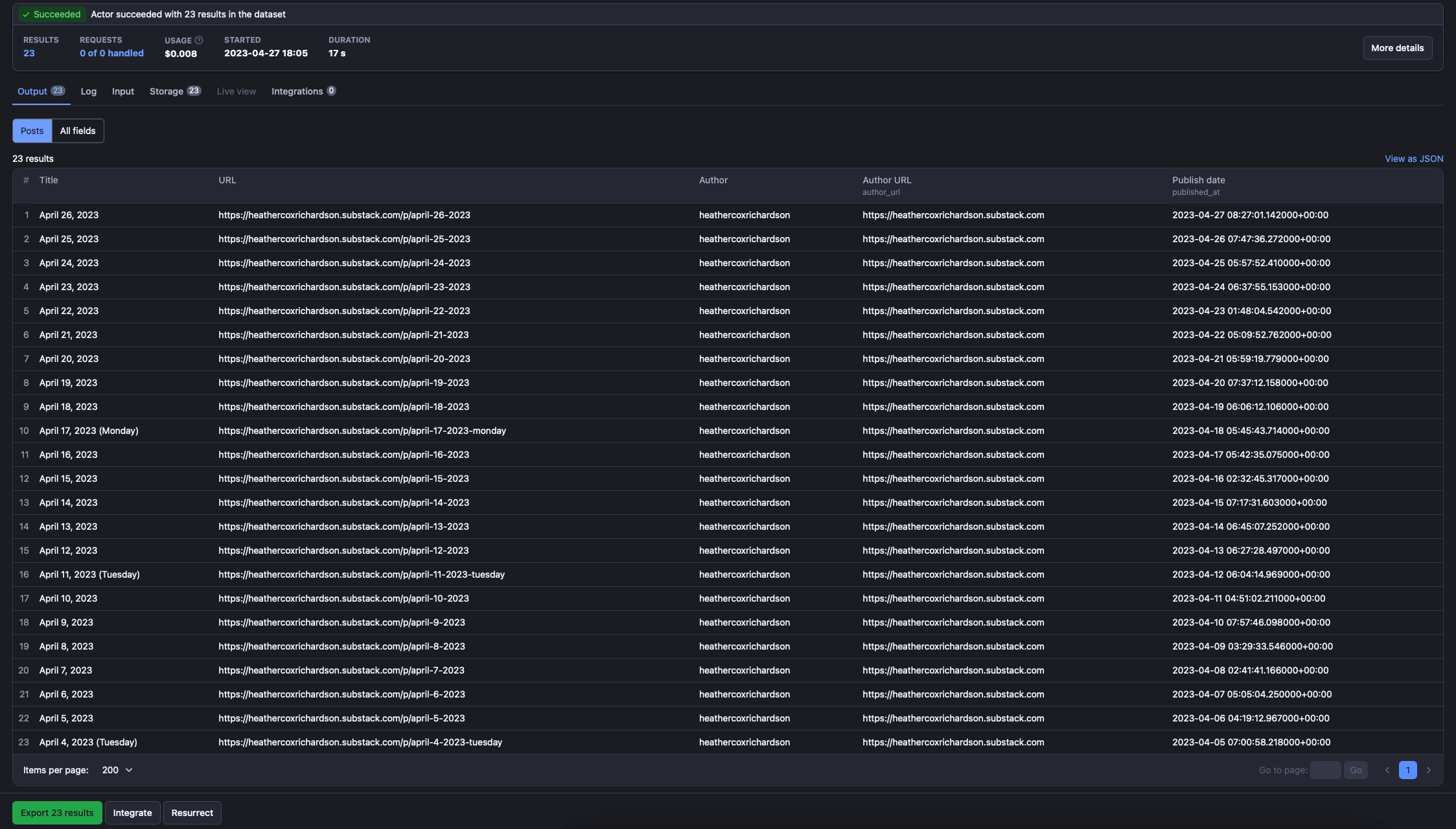
Example :
1[{ 2 "title": "April 26, 2023 ", 3 "subtitle": "", 4 "url": "https://heathercoxrichardson.substack.com/p/april-26-2023", 5 "author": "heathercoxrichardson", 6 "author_url": "https://heathercoxrichardson.substack.com", 7 "published_at": "2023-04-27 08:27:01.142000+00:00" 8}, 9{ 10 "title": "April 25, 2023", 11 "subtitle": "", 12 "url": "https://heathercoxrichardson.substack.com/p/april-25-2023", 13 "author": "heathercoxrichardson", 14 "author_url": "https://heathercoxrichardson.substack.com", 15 "published_at": "2023-04-26 07:47:36.272000+00:00" 16}]
Usage
To use this actor, simply provide the required input properties and run the actor. You can customize the input properties to limit the number of posts or include/exclude the article content in the results as needed.
Once the actor has completed its run, the scraped data will be available in the specified output format, making it easy to analyze, process, or store the information for further use.
Contact us ?
Any project or questions ?
📧 quentin.payre.entreprise@gmail.com Telegram @quentinpjf
Frequently Asked Questions
Is it legal to scrape job listings or public data?
Yes, if you're scraping publicly available data for personal or internal use. Always review Websute's Terms of Service before large-scale use or redistribution.
Do I need to code to use this scraper?
No. This is a no-code tool — just enter a job title, location, and run the scraper directly from your dashboard or Apify actor page.
What data does it extract?
It extracts job titles, companies, salaries (if available), descriptions, locations, and post dates. You can export all of it to Excel or JSON.
Can I scrape multiple pages or filter by location?
Yes, you can scrape multiple pages and refine by job title, location, keyword, or more depending on the input settings you use.
How do I get started?
You can use the Try Now button on this page to go to the scraper. You’ll be guided to input a search term and get structured results. No setup needed!