Tripadvisor Scraper
Scrape data from tripadvisor.com at fixed cost. Extract hotels, restaurants, attractions and vacation rentals from listing pages. Get contact number, email, rating, reviews, offers, amenities, etc.
Overview
Tripadvisor Scraper is an Apify actor that allows you to efficiently scrape data from the Tripadvisor website. This powerful tool is designed for various use cases, including extracting information such as names, categories, addresses, emails, ratings, awards, and many more attributes of hotels, restaurants, vacation rentals listed on the Tripadvisor platform.
With Tripadvisor Scraper, you have the flexibility to either search for a specific location and retrieve data from the dataset or send a synchronous request to the Actor endpoint to scrape detailed information about a single place, such as a hotel or restaurant, in just 15 seconds.
Supported Data Extraction
You can extract a wide range of data from Tripadvisor, including:
- 🏨 Hotels
- ☕️ Restaurants
- 🛫 Vacation rentals
- 🏞️ Attractions
How to Use Tripadvisor Scraper
You can utilize Tripadvisor Scraper in two primary ways:
- Search URLs: You can provide search URL from the Tripadvisor website, including hotels search, places search, trips with search filters.
For detailed guidance on configuring input fields and examples, please refer to the Input page.
If you are interested in scraping similar websites, you must also check out Booking.com Scraper which helps in scraping booking.com including stays, hotels, attractions
Maximum Results
The number of results you can scrape with Tripadvisor Scraper can vary significantly based on factors such as the input complexity, location, and website limitations. While the actor is designed to handle a large volume of data, it's important to note that:
- Tripadvisor's website may display different results based on input type and value.
- Tripadvisor may have internal limits that affect the scraping results.
- The actor itself may have limitations that are continually being improved.
For the most accurate results for your specific use case, it is recommended to perform a test run to determine the maximum number of results achievable.
Tripadvisor's Hotel Results Limit
Tripadvisor imposes a limit of approximately 3000 hotels per country/region. To overcome this limitation, you should split your searches into deeper city searches and let the scraper scrape all hotels for each city within your specified location, ensuring you receive all available results.
Input Configuration
When running Tripadvisor Scraper, you can configure what data to scrape and how to extract it. Input can be provided in either a JSON file or through the Apify platform's editor. Most input fields have reasonable default values. For detailed descriptions and examples of input fields, refer to the screenshot below or visit the Input page.
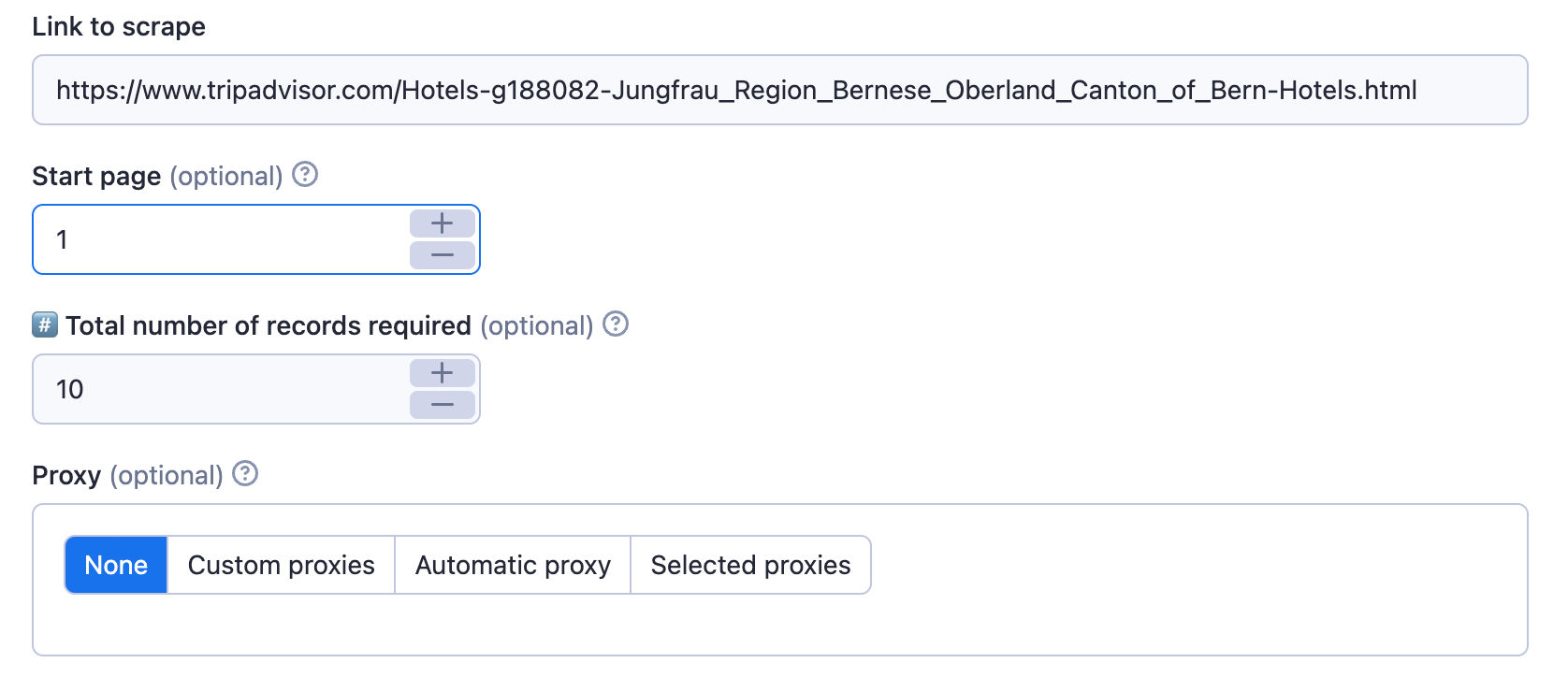
Scraping with search URL
Tripadvisor Scraper supports various types of search URLs that can be provided using the searchUrl input field. Examples include hotels, places, trips.
Sample Output
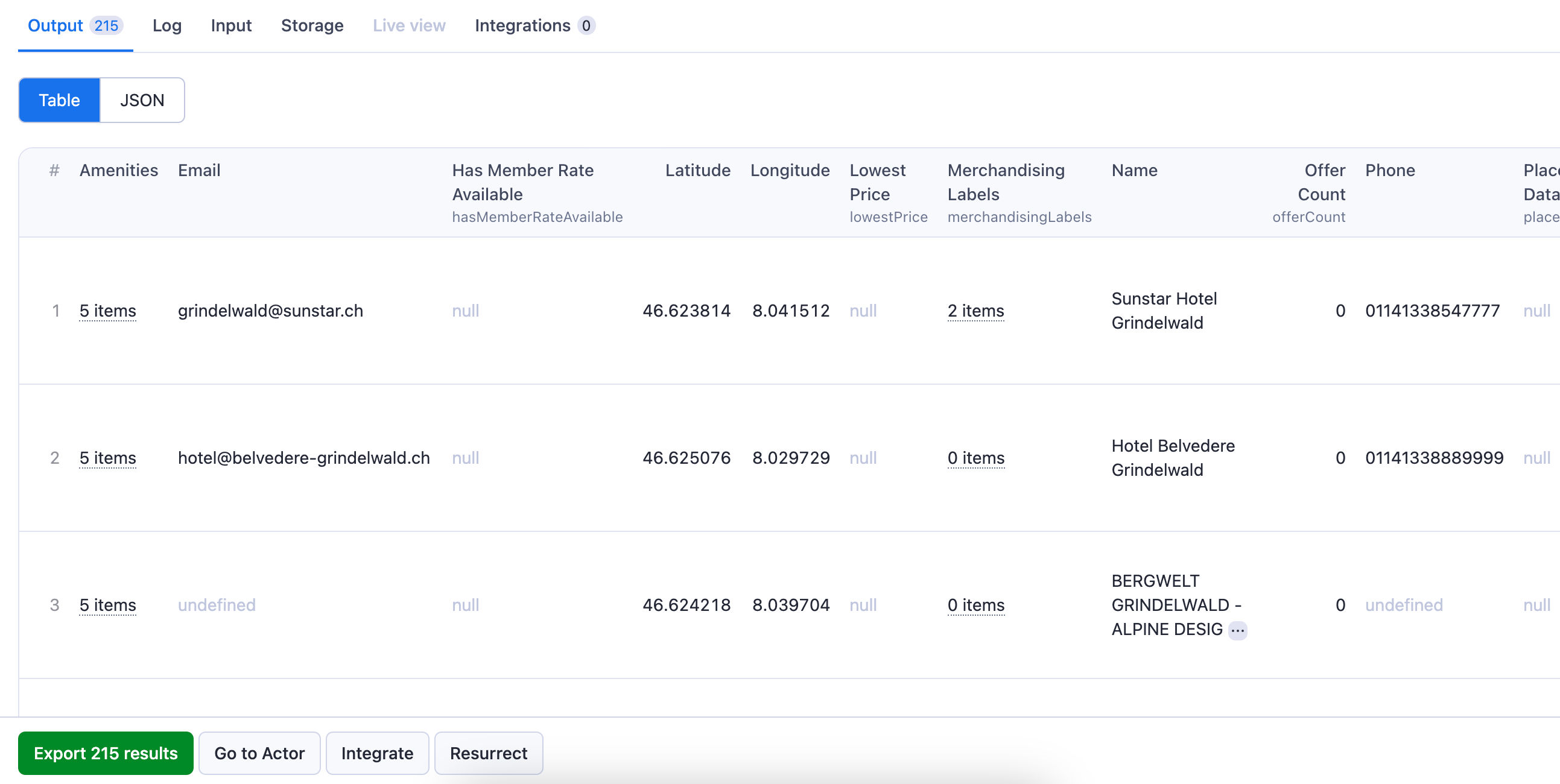
Here is a sample of the type of data you can expect to extract with Tripadvisor Scraper:
1{ 2 "name": "Sunstar Hotel Grindelwald", 3 "rating": 4, 4 "reviewCount": 806, 5 "popIndexRank": 14, 6 "popIndexTotal": 42, 7 "thumbnail": "https://dynamic-media-cdn.tripadvisor.com/media/photo-o/29/80/9d/6d/c84023-exterior.jpg?w=1200&h=800&s=1", 8 "latitude": 46.623814, 9 "longitude": 8.041512, 10 "telephone": "+41 33 854 77 77", 11 "streetAddress": { 12 "street1": "Dorfstrasse 168", 13 "street2": null, 14 "city": "Grindelwald", 15 "state": null, 16 "country": "Switzerland", 17 "postalCode": "3818", 18 "fullAddress": "Dorfstrasse 168, Grindelwald 3818 Switzerland" 19 }, 20 "amenities": [ 21 { 22 "icon": "wifi", 23 "tagId": 9176, 24 "amenityName": "Free Wifi" 25 }, 26 { 27 "icon": "coffee-tea-cafe", 28 "tagId": 9179, 29 "amenityName": "Breakfast included" 30 }, 31 { 32 "icon": "pool", 33 "tagId": 6217, 34 "amenityName": "Pool" 35 }, 36 { 37 "icon": "restaurants", 38 "tagId": 9165, 39 "amenityName": "Restaurant" 40 }, 41 { 42 "icon": "bell", 43 "tagId": 9161, 44 "amenityName": "Room service" 45 } 46 ], 47 "merchandisingLabels": [ 48 { 49 "id": "BEST_SELLER", 50 "text": "Best Seller", 51 "description": "This is one of the most booked hotels in Grindelwald over the last 60 days." 52 }, 53 { 54 "id": "BREAKFAST_INCLUDED", 55 "text": "Breakfast included", 56 "description": null 57 } 58 ], 59 "specialOffer": null, 60 "email": "grindelwald@sunstar.ch", 61 "phone": "0041338547777", 62 "placementListingData": null, 63 "hasMemberRateAvailable": null, 64 "providerNameWhoHasMemberRate": null, 65 "lowestPrice": null, 66 "offerCount": 0, 67 "primaryOffers": [], 68 "secondaryOffers": [] 69}
Frequently Asked Questions (FAQ)
Can I integrate Tripadvisor Scraper with other apps?
Yes, Tripadvisor Scraper can be integrated with various cloud services and web apps through Apify's integrations. You can connect it with tools like Make, Zapier, Slack, Airbyte, GitHub, Google Sheets, Google Drive, and more. Additionally, you can use webhooks to trigger actions whenever a scraping run is completed successfully.
Can I use Tripadvisor Scraper with the API?
Absolutely. The Apify API provides programmatic access to the Apify platform, allowing you to manage, schedule, and run Apify actors. You can access datasets, monitor actor performance, fetch results, create and update versions, and more. To access the API using Node.js, use the apify-client NPM package, or use the apify-client PyPI package for Python.
Is it legal to scrape tripadvisor ?
Our scrapers are ethical and do not extract any private user data, such as email addresses, gender, or location. They only extract what the user has chosen to share publicly. We therefore believe that our scrapers, when used for ethical purposes by Apify users, are safe. However, you should be aware that your results could contain personal data. Personal data is protected by the GDPR in the European Union and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, consult your lawyers. You can also read our blog post on the legality of web scraping
Your feedback
We’re always working on improving the performance of our Actors. So if you’ve got any technical feedback for this scraper or simply found a bug, please create an issue on the actor’s Issues tab in Apify Console.
Thank you for choosing Tripadvisor Scraper for your web scraping needs! Happy scraping! 🚀
Frequently Asked Questions
Is it legal to scrape job listings or public data?
Yes, if you're scraping publicly available data for personal or internal use. Always review Websute's Terms of Service before large-scale use or redistribution.
Do I need to code to use this scraper?
No. This is a no-code tool — just enter a job title, location, and run the scraper directly from your dashboard or Apify actor page.
What data does it extract?
It extracts job titles, companies, salaries (if available), descriptions, locations, and post dates. You can export all of it to Excel or JSON.
Can I scrape multiple pages or filter by location?
Yes, you can scrape multiple pages and refine by job title, location, keyword, or more depending on the input settings you use.
How do I get started?
You can use the Try Now button on this page to go to the scraper. You’ll be guided to input a search term and get structured results. No setup needed!