
Y Combinator Scraper
Scrape data on Y Combinator companies and their founders from the YC startup directory.
What does Y Combinator Scraper do?
Y Combinator Scraper allows you to extract data about companies and founders from the Y Combinator directory: company name, description, batch, status, location, open jobs, website, founder name, founder LinkedIn, and more.
About Y Combinator
Y Combinator is the leading startup accelerator for entrepreneurs. Since 2005, YC has invested in over 4,500 companies that have a combined valuation of over $600B, including Airbnb, Dropbox, Stripe, Reddit, Instacart, DoorDash, and Coinbase. Today, YC has built the most powerful startup community in the world alongside the products and programs to support founders for the life of their company.
Company data fields
| Field Name | Type | Description |
|---|---|---|
| Company Name | String | Company name |
| Short Description | String | One-line description of the company |
| Long Description | String | Long description of the company |
| Batch | String | Batch name provided by YC |
| Status | String | Company status |
| Tags | List | Industry tags |
| Location | String | Company location |
| Year Founded | Int | Year the company was founded |
| Team Size | Int | Number of employees |
| Primary Partner | String | Mentor for a company |
| Website | String (URL) | Company website |
| Company LinkedIn | String (URL) | Company LinkedIn URL |
| Company X | String (URL) | Company X URL |
Open Jobs data fields
| Field Name | Type | Description |
|---|---|---|
| Is Hiring | Boolean | Hiring status (true/false) |
| Number of Open Jobs | Int | Count of open job positions |
| Open Jobs | List | List of current job openings |
Founders data fields
| Field Name | Type | Description |
|---|---|---|
| Founder Name | String | Founder name |
| Founder LinkedIn | String (URL) | Founder LinkedIn URL |
| Founder X | String (URL) | Founder X URL |
Why scrape Y Combinator?
- Lead generation: identifying startups for potential collaboration or investment.
- Market research: analyzing trends and popular niches in the startup ecosystem.
- Studying the startup landscape: understanding successful approaches and business models.
- Finding inspiration: exploring ideas and innovations that could influence your own project.
Example Input
Companies search URL: https://www.ycombinator.com/companies?batch=F24&industry=B2B

And here’s the same, just in JSON.
1{ 2 "number_of_founders": 1, 3 "scrape_open_jobs": true, 4 "url": "https://www.ycombinator.com/companies?batch=F24&industry=B2B" 5}
Output sample
The results will be wrapped into a dataset which you can find in the Storage tab. Note that the output is organized in a table for viewing convenience. Here's an example of some of the output from the previous companies search URL:
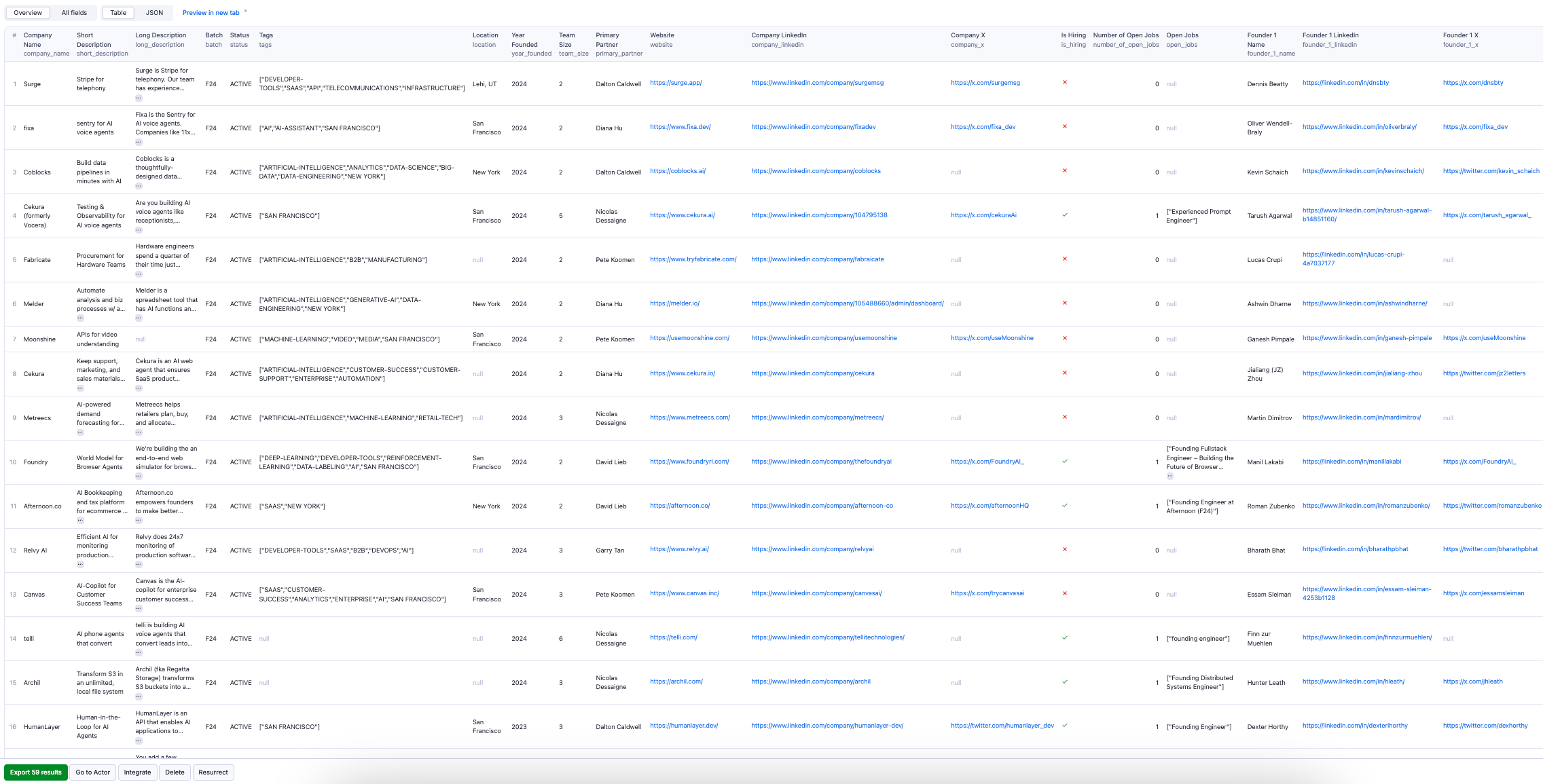
By clicking on the green Export button, you can download the dataset in XML, CSV, Excel, HTML, or JSON. See an example of a JSON file:
1{ 2 "company_name": "HumanLayer", 3 "short_description": "Human-in-the-Loop for AI Agents", 4 "long_description": "HumanLayer is an API that enables AI applications to contact humans for help, feedback, and approvals. One customer uses HumanLayer to ship DevOps agents that manage complex and risky workflows like production deployments and database migrations. \r\n\nWe’re building HumanLayer because we know that the future of AI Applications is not gonna be humans sitting at a chat interface, the future is “outer loop” or “headless” agents, and our partners are building AI apps that invert the typical interaction paradigm. Autonomous agents are calling humans, not the other way around.\r\n\nAI Agents are poised to disrupt the $4.6tn global labor market, but in order to make agents reliable today, and train them to be fully autonomous tomorrow, solutions like HumanLayer are an inevitable part of the AI Agent stack.", 5 "batch": "F24", 6 "status": "ACTIVE", 7 "tags": [ 8 "SAN FRANCISCO" 9 ], 10 "location": "San Francisco", 11 "year_founded": "2023", 12 "team_size": "3", 13 "primary_partner": "Dalton Caldwell", 14 "website": "https://humanlayer.dev", 15 "company_linkedin": "https://www.linkedin.com/company/humanlayer-dev/", 16 "company_x": "https://twitter.com/humanlayer_dev", 17 "is_hiring": true, 18 "number_of_open_jobs": 1, 19 "open_jobs": [ 20 "Founding Engineer" 21 ], 22 "founder_1_name": "Dexter Horthy", 23 "founder_1_linkedin": "https://linkedin.com/in/dexterihorthy", 24 "founder_1_x": "https://twitter.com/dexhorthy" 25}
How do I use Y Combinator Scraper?
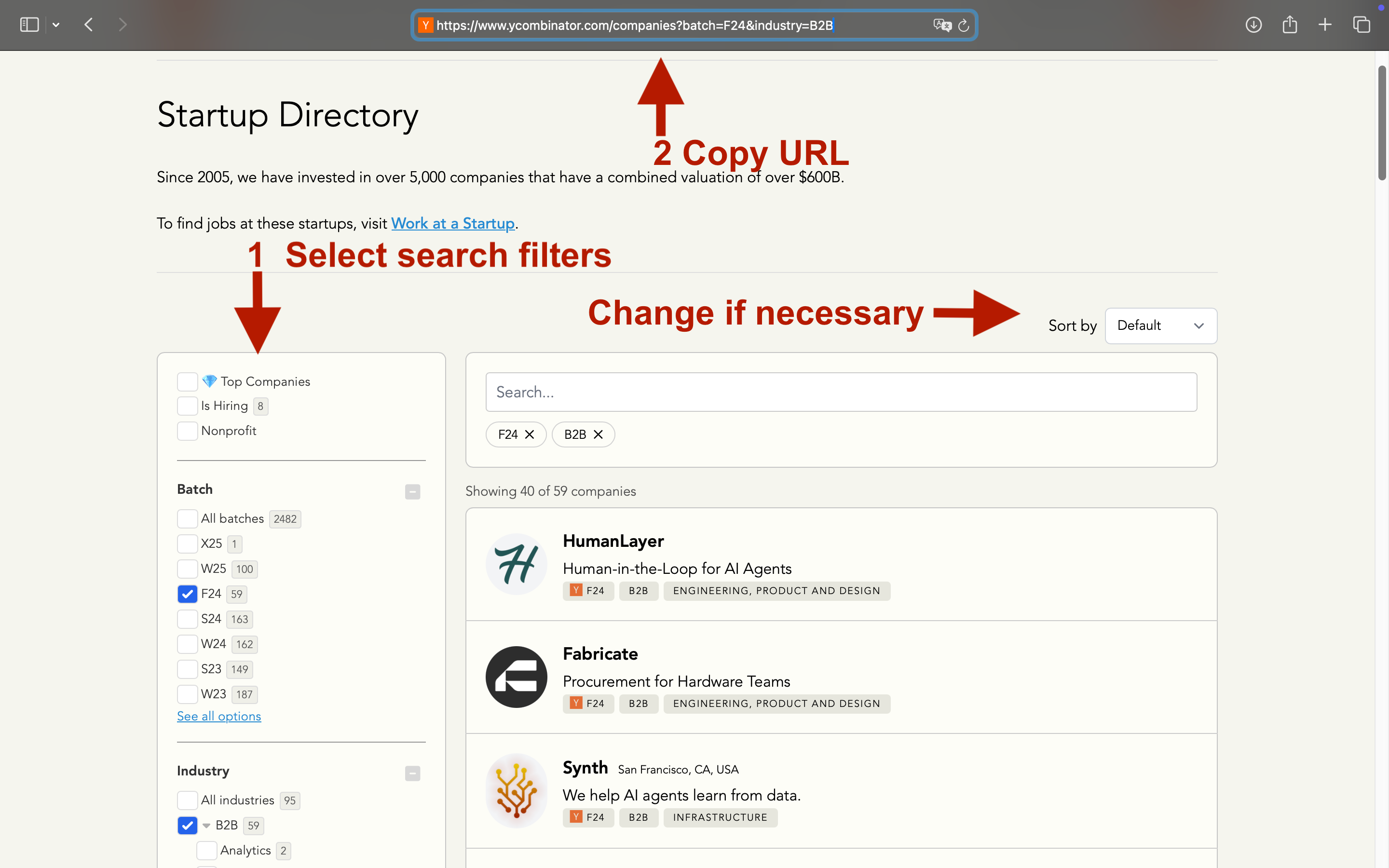
The Y Combinator Scraper is designed to help you easily extract contact details from the web, even if you have no prior experience. Follow these steps to scrape data on Y Combinator companies and their founders:
- Enter Search URL: Copy and paste the Y Combinator directory search URL directly into the scraper's input field.
- Select Founder Quantity: Choose the number of founders (up to 4) you want to extract from the search results.
- Enable 'Scrape Open Jobs': Set this feature to true if you want to get information about open job positions at the companies.
- Run the Scraper: Click "Start" and wait for the data extraction to complete.
- Export your data in Excel, CSV, JSON, HTML, or via API.
After selecting the necessary filters, the URL address may not update immediately from time to time. Therefore, please double-check it before pasting it into the scraper. Additionally, you can change the "Sort by" option as shown in the screenshot to ensure that the URL address updates promptly based on the filters you have selected.
How much does Y Combinator Scraper scraping cost?
This scraper uses the Pay-per-result pricing model, so your costs can be easily calculated: it will cost you $15 to scrape 1,000 search results, which is $0.015 per item. Apify provides you with $5 in free usage credits every month on the Apify Free plan, allowing you to scrape over 300 search results from the Y Combinator directory for free using those credits.
For regular data extraction, consider upgrading to the $49/month Starter plan, which can get you over 3,000 search results every month.
Integrations and Y Combinator Scraper
Y Combinator Scraper can be connected with almost any cloud service or web app thanks to integrations on the Apify platform. You can integrate with Make, Zapier, Slack, Airbyte, GitHub, Google Sheets, Google Drive, and more.
Your feedback
We’re always working on improving the performance of our Actors. If you’ve got any technical feedback for Y Combinator Scraper or simply found a bug, please create an issue on the actor’s Issues tab in Apify Console.
Frequently Asked Questions
Is it legal to scrape job listings or public data?
Yes, if you're scraping publicly available data for personal or internal use. Always review Websute's Terms of Service before large-scale use or redistribution.
Do I need to code to use this scraper?
No. This is a no-code tool — just enter a job title, location, and run the scraper directly from your dashboard or Apify actor page.
What data does it extract?
It extracts job titles, companies, salaries (if available), descriptions, locations, and post dates. You can export all of it to Excel or JSON.
Can I scrape multiple pages or filter by location?
Yes, you can scrape multiple pages and refine by job title, location, keyword, or more depending on the input settings you use.
How do I get started?
You can use the Try Now button on this page to go to the scraper. You’ll be guided to input a search term and get structured results. No setup needed!